
LinkedIn的使命是连接世界上的专业人士,让他们更有效率、更成功。变得更有效率和成功是一个终生的旅程。在这个过程中,用户会以不同的方式利用LinkedIn,比如建立自己的职业网络、学习新技能、展示个人资料、寻找工作,以及了解自己的行业。当会员经历这些不同的阶段时,他们有时会从指引中获益,了解如何从LinkedIn实现更多价值。提供这种指导是一个雄心勃勃的目标,因为每个会员都是不同的,每个用户在他们的旅程中都处于不同的阶段,在每个阶段都有几种方式从LinkedIn获取更多有价值的东西。
幸运的是,我们配备了非常适合这类任务的人工智能算法。这些算法可以了解从LinkedIn中实现价值的成员如何利用该平台,然后这些学习可以用来设计干预措施,引导其他成员以类似的方式利用LinkedIn。在这篇博文中,我们解释了基于人工智能的四步方法,用来帮助我们的会员实现LinkedIn的增值。
图1 基于AI的四步走方法帮助用户更好的使用Linkedin
第一步:定义要优化的指标
我们从定义成功的目标指标开始。有几种方法可以衡量一个用户是否在LinkedIn上实现了价值。当我们第一次实现我们的方法时,我们假设一个用户在一周内至少访问一次LinkedIn,那么该用户就实现了LinkedIn的价值。因此,在我们寻求提高从LinkedIn获得价值的成员数量时,我们寻求最大限度地增加每周活跃用户(wau)的数量。这让我们能够根据可量化的成功指标来定义目标。(要优化的目标,可能是观察指标,不能对其直接进行优化。比如ctr指标,这个指标是可以直接进行优化,我们点击样本为正,非点击样本为负,构建一个模型,来提升ctr指标。但是对于留存的直接优化,略有困难,不知道从哪里下手。有这样一个猜想,以留存为正样本,非留存为负样本,这样粗暴的建模,能够可行?这样做要求的特征工程是否需要比较复杂、完美?有时间我要去尝试尝试)
步骤2:找到与观察指标密切相关的特征
接下来,我们训练了一个“每周活跃概率”模型(以下简称pWA模型),用来预测用户在下周活跃的概率。我们为这个模型准备了如下的训练示例。对于每个用户,我们构造了大量的特征,并观察他们在接下来七天的活跃度,以准备标签。如果该用户在7天内处于活动状态(访问LinkedIn),则该标签为1,否则为0。我们整理了以下五种类型的特征:
-
Profile features, 如行业、技能、档案完整性等。
-
Asset features, 如成员是否有手机应用,成员是否有付费订阅等。
-
Activity features,比如过去N天的会话数量, 在过去N天看来来看招聘jd的人,在过去N天收到的招聘拟jd数量,在过去N天跟feed流交互情况,在过去N天在feed流中共享的文章数量,等等。
-
Liquidity features, 例如成员在过去N天内收到的各种类型的通知数量,成员feed中的更新数量等。
-
Network features, 如连接数、活跃的连接数、用户关注的人的数量、成员所属的组数等。
通过这些训练示例,我们训练了一个XGBoost分类模型。在这个模型训练之后,我们根据它们在模型中的重要性对特征进行排序,以确定一组与用户在下周活跃的概率强相关的特征。该集合的部分功能包括:成员是否有移动应用、最近N天的会话数、成员最近N天收到的各种类型的通知数、活跃的连接数。举个简单的例子,我们可以说,如果一个成员拥有手机应用,那么这个成员很有可能在下周活跃起来。类似地,如果一个用户有少量活跃的连接,那么该成员在下一周内不太可能活跃。
步骤3:评估每个强相关特征对指标的影响
接下来,对于上述集合中的每个特性,我们考虑是否有可能通过干预直接改变该特性的值。如果是,那么我们就保留这一功能;否则,我们就删除它。例如,我们保持特性”成员是否有手机应用程序,“我们可以推动一个成员通过提示安装手机应用程序web应用程序,但是我们删除功能”过去N天的会话数量”,正如我们不能直接创建一个干预来改变这个功能的价值。现在,对于这个更小的特征子集中的每个特征,我们进行了一个观测因果分析,以粗略估计特征值的变化对我们的成功度量(WAUs)的预期影响。这是必要的一步,因为相关性并不一定意味着因果关系。例如,基于相关性,我们可以说,如果一个成员有少量活跃的连接,那么该成员在下一周内不太可能活跃。然而,在没有进一步分析的情况下,我们不能说如果该成员增加了更多跟活跃用户的联系,那么该成员在下周活跃的可能性是否会增加。因此,这就是我们如何估计“活跃连接数”特性值变化的预期影响。我们随机选择了一个日期d。然后,我们查看了围绕那个日期的历史数据,并将我们的成员分成两组:
组1:在日期d至日期d+7期间与至少一个活跃成员(在日期d前一周至少访问一次LinkedIn的会员)建立联系的会员。
第2组:在第d天和第7天之间没有联系任何活跃成员的成员。
然后,我们计算了在d日之前的一周和d+7日之后的一周内各组的wau数量。
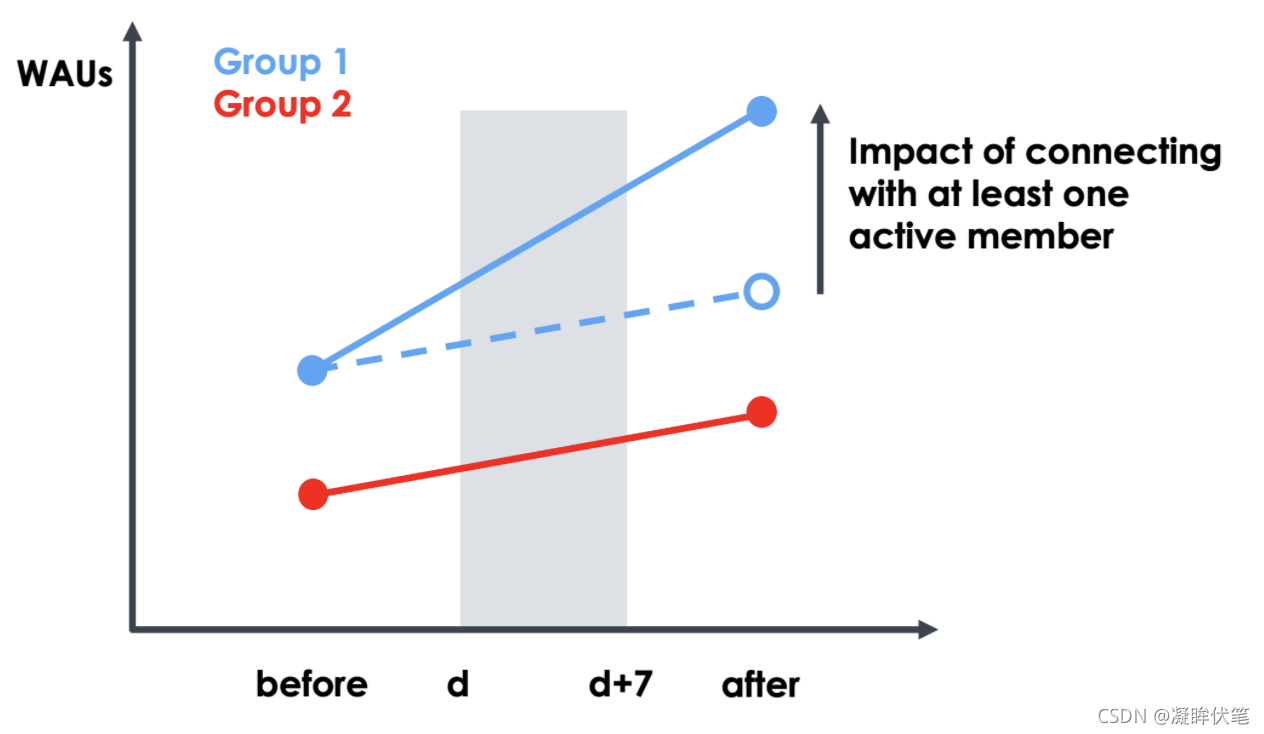
Figure 2: Estimating the impact of an increase in the value of the feature “number of connections who are active” on the WAUs metric from historical data
由此,我们计算出“活跃连接数”特性值增加的预期影响如下:
[WAUs(Group 1, after) - WAUs(Group 1, before)] - [WAUs(Group 2, after) - WAUs(Group 2, before)]
这个公式的第一部分捕获了由于与至少一个活跃成员连接而导致的wau的变化,以及其他可能的因素。公式的第二部分捕获了除了与活跃成员联系以外的其他因素导致的wau的变化。
在对子集中的每个特性运行这种类型的分析之后,我们根据它们的值变化对我们的成功度量的预期影响对特性进行排序。
步骤4:设计干预措施,使得对目标的影响最大化
接下来,对于每个对我们的成功度量有很大影响的功能,我们设计了干预(或实验)来改变它的值。例如,“活动的连接数”对wau有很大的预期影响。因此,我们设计了一个干预来促进该功能值的更改,如下所示。
我们的“你可能认识的人”(PYMK)推荐信会推荐会员可能想要联系的人。粗略地说,这个推荐人之前通过推荐最有可能收到和接受该成员邀请的人来最大化平台成员之间的联系总数。为成员推荐候选人的分数计算如下:
score(候选人)= pConnect(用户,候选人)
其中pConnect(用户,候选人)是成员和候选人之间形成连接的概率。
尽管这样做是为了最大限度地增加连接的数量,但并不一定是为了最大限度地增加每个成员的价值。例如,如果Alice和Bob在现实生活中是好朋友,那么Bob就会被推荐给Alice使用上面的打分函数,因为Alice很有可能向Bob发送邀请,Bob很有可能接受Alice的邀请。然而,如果Alice目前正在找工作,那么她可能不会意识到与Bob联系的价值,而是与潜在雇主联系。为了使每个成员实现的价值最大化,我们将成功度量(WAUs)最大化作为一个新的目标。这产生了一个新的计分函数,为新的目标增加了一个术语:
score(candidate) = pConnect(member, candidate) +
𝛼 [ΔpWA(member | member-candidate) + ΔpWA(candidate | member-candidate)]
- Equation (1)
其中ΔpWA(用户|用户-候选人)是如果成员和候选人之间形成了连接,则该成员将在下一周内活跃的预期概率变化,ΔpWA(候选人 | 用户-候选人)是如果成员和候选人之间形成了连接,则该候选人将在下周活跃的预期概率变化。
注意,在这个评分函数中,我们捕获了候选人和成员之间的连接对成员和候选人的每周活跃度的影响。此外,我们引入了一个参数𝛼。这个参数控制了wau的新目标和之前的连接数目标之间的权衡。在上面的例子中,用潜在雇主替换Bob可能会减少形成的连接数,因为Alice可能不会向该潜在雇主发送邀请,或者该潜在雇主可能不会接受Alice的邀请。
现在,为了能够使用公式(1)对每个候选推荐打分,我们需要预测ΔpWA(P | P- q)的能力,即,预期变化的概率P一员将在下周如果连接活跃成员之间形成P和另一个成员问:学习模型等进行预测是一个重要的运动,因为我们没有训练该模型所需的所有信息在我们的历史数据。例如,假设历史数据中的成员a在日期d时与成员B连接。然后,为了从该事件创建一个培训示例,我们需要为该培训示例使用以下标签,以准确捕捉a由于与B的连接而导致的每周活跃度的变化:
label = (weekly activeness of A after date d) -
(weekly activeness of A after date d if A had not connected with B)
问题在于,虽然观察到了(A在d天后的周活跃行为),但却没有观察到相反的(如果A没有与B联系,A在d天后的周活跃行为)。为了得到一个准确的估计的反事实的,我们必须找到另一个用户的相同一个日期d但没有联系B,然后看看观察每周主观能动性的日期后d。然而,找到一个“并不容易。因此,我们假设(A在d天后的周活跃行为)与(如果A没有与B联系的话,A在d天后的周活跃行为)是一个很好的近似。
基于这个假设,我们从历史数据中的每个连接事件A-B准备了两个训练示例:一个用于A的每周活跃度变化,另一个用于B的每周活跃度变化,这是由于连接A-B造成的。每个培训的示例中,我们使用特性类似于市政工程局的A和B两个实体模型,以及一些特性,如概要文件之间的相似度和B与这些训练的例子,我们训练一个XGBoost模型ΔpWA (P | P q)。
我们的模型学习到了一些不错的模式,比如:
ΔpWA(P | P-Q)高,如果P是一个不太活跃的求职者(浏览了过去的一些工作)(最近的几次),Q是一个工作海报(发布了过去的工作)(最近的几次)。
ΔpWA(P | P-Q)是高的,如果P是一个不太活跃的内容消费者(过去的一些feed交互)(最近的一些会话),而Q是一个活跃的内容生产者(feed中的共享内容)(最近的一些会话)。
通过方程(1)中的模型,我们可以看到,如果一个成员目前正在寻找一份工作,在他们的旅程中变得更有成效和成功,那么我们的干预应该帮助他们与积极的招聘人员和招聘经理联系。该成员应该在PYMK推荐中看到更多活跃的招聘人员和招聘经理,也应该出现在活跃的招聘人员和招聘经理的PYMK推荐中。然后,一旦这个成员找到了工作,并开始寻找他们行业的新闻,我们的干预应该帮助他们与积极制作内容的个人联系起来。
当我们实施干预措施时,我们确实看到了wau数量的增加,但我们也看到了连接数量的轻微下降。我们调整了方程(1)中的参数α,以达到两个目标之间可接受的折衷。
类似地,我们设计了其他干预措施,以改变对wau有很大预期影响的其他特征的值。值得指出的是:
预测非个性化干预的影响(ΔpWA)相对简单得多。例如,预测的影响促使成员安装手机应用程序在web应用程序通过一个提示,我们可以简单地运行一个实验显示该提示一小部分随机选择成员,然后比较这些成员的每周活性治疗组与对照组的成员。这种比较可以对具有任何选定特征的成员进行——例如,在实验开始前从事互联网行业的治疗组成员和对照组成员。
对于已经非常活跃的会员,或者换句话说,已经从LinkedIn中实现了巨大价值的会员,ΔpWA的大多数干预应该接近于0。
学习
以下是经验总结:
1.尽早选择一个成功指标是非常重要的,因为如果没有它,就很难取得进展。对于成功指标,通常有很多选择,但最好选择一个与产品使命相符且易于观察的指标。
2.训练一个具有大量成员特征的简单相关模型,有助于缩小可能干预的搜索空间。
3.改变与成功指标密切相关的功能的价值并不一定会改善成功指标;因此,最好是通过观察的因果分析来评估每个强相关特征值的任何变化对成功度量的影响。
4.当试图改变特征的值时,干预措施需要仔细设计,因为这些特征会对成功度量产生很大的预期影响。最好是将成功指标的最大化作为一个目标添加到系统中,通过这个目标,干预将被交付。
5.在为模型准备训练数据以预测干预对成员的影响时,通常需要做出某些假设(取决于干预的类型)。
6、为了改进特定群体成员(如学生)的成功度量,可以对这些成员重新进行相关性和观察性因果分析,以确定对该群体有很大预期影响的特征。
最终,根据不同用户算法如何利用产品实现其目标的历史数据,帮助找到有影响力的干预措施。当然可以有许多其他有影响力的干预措施,以新的方式增强用户体验,例如新的产品功能,重新设计用户界面,等等。
原文:Helping members connect to opportunity through AI | LinkedIn Engineering