
1. 写在前面
在推荐领域,我们往往也会听到建立什么倒排索引,方便查找啥的, 之前一直对这一块感觉很迷糊, 到底啥子叫倒排索引,啥子又叫正排索引, 建立倒排索引的意义在哪? 所以这篇文章, 简单的通过查阅资料对这两个概念理解下。
下面是我基于查的资料自己给出的理解哈,可能不一定对。
正排和倒排索引,是文件检索系统领域比较重要的两种数据结构,而我理解,其实是两种为了高效查询而存在的两种不同的组织形式, 建立的是文档与单词之间的映射关系。
- 正排索引:
文档->关键词之间的映射,也就是我们输入文档编号, 会得到文档内容, 文档关键词等信息,比较典型的,就是{doc: [word1, word2, ..]}, 放到推荐里面, 可能对应{item: [feature1, feature2, ...]} - 倒排索引: 关键词->文档之间的映射,也就是我们如果输入关键词, 会找到对应的文档信息, 比较典型的
{word: [doc1, doc2, ...]}, 放到推荐里面, 可能对应{user_id: [item1, item2, ..]}
既然这玩意是来自文档检索领域,那么我们就从文档检索上开始理解。
搜索引擎中, 每个文件对应一个文件ID, 文件内容被表示为一系列关键词的集合。
2. 正排索引
为该文档(页面)建立与关键词的对应关系, 结构如下:
正排索引: 由文档指向关键词
文档--> 单词1 ,单词2
单词1 出现的次数 单词出现的位置; 单词2 单词2出现的位置 ...
正排索引: 在搜索栏中输入id查词条(已知id)
换成图片表示的话:

当用户在搜索框中输入"关键词"的时候, 假设只存在正向索引(forward index), 那么就需要扫描索引库中的所有文档,找出所有包含"关键词"的文档,再根据打分模型进行打分,排出名次后呈现给用户。
但是呢? 互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
而这里如果我们再对比到推荐领域的话,这里的文档,是不是像我们要推荐的item? 而这里的关键词,是不是像我们推荐领域的user_id, 上面根据关键词给出相关文档的过程,像不像给定user_id, 推荐系统给他推荐相关的item_list呢? 论类比的重要性。
3. 倒排索引
用户在搜索引擎中搜关键词的时候,搜索引擎就会把和关键词有关的文档(页面)展现给用户,这个过程就是倒排索引, 由关键词指向文档或者文件。
结构如下:
倒排索引: 由关键词指向文档
单词1--->文档1,文档2,文档3
单词2--->文档1,文档2
倒排索引: 将搜索框中的词进行搜索查到哪些id包含这个词,再查这些id(通过分词查id)
从词的关键词,去找文档。图表示的话如下:

所以, 当用户搜索某个关键词的时候, 系统就立刻在倒排索引中定位这个关键词, 马上找到包含这个关键词的页面。
倒排索引有着广泛应用场景: 搜索引擎, 大规模数据库索引, 文档检索, 多媒体检索等。
正排索引: 文档 --> 单词
倒排索引: 单词 --> 文档
4. 简单实例
下面用个小例子, 来看下正排和倒排索引了。
假设文档集合包含五个文档, 每个文档内容如下(图片来自下面第一个链接):

那么对于正排索引, 应该是下面这样的存储方式:
文档编号 正排列表
1 谷歌->地图->之父->跳槽->Facebook
2 谷歌->地图->之父->加盟->Facebook
3 谷歌->....
4
5
而倒排索引:
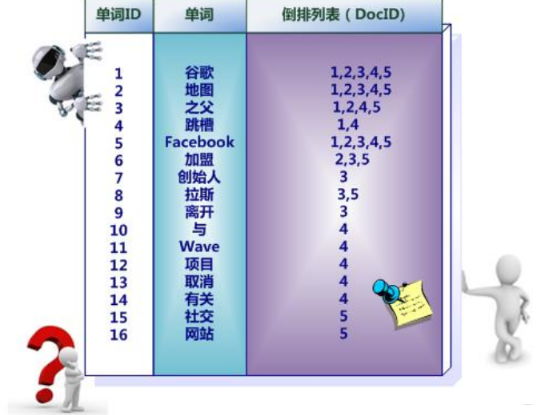
除此之外, 索引系统还可以记录更多的信息,比如在单词对应的倒排列表中不仅记录文档编号, 还可以记载单词频率信息(TF), 即这个单词在某个文档中出现的次数,之所以记录这个信息, 是因为词频信息在搜索结果排序时,计算查询和文档相似度是很重要的一个计算因子。
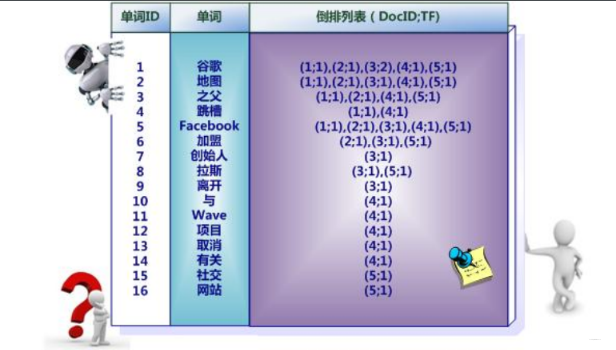
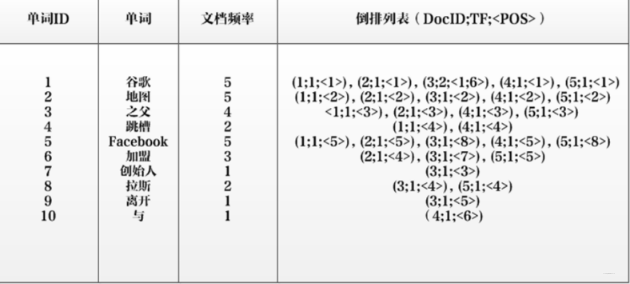
更加完备的倒排索引结构, 还可以记录更多的信息, 有的除了记录文档编号和单词频率之外,还额外记载了每个单词对应的文档频率信息以及在倒排列表中记录单词在某个文档中出现的位置。
- 文档频率信息: 代表了在文档集合中有多少个文档包含某个单词,之所以要记录这个信息,是因为这个信息在搜索结果排序中也是一个非常重要的因子
- 单词在某个文档中出现的位置信息并非一定要记录, 可以有可以没有。
比如, 以单词"拉斯"为例, 其单词编号是8, 文档频率是2, 代表整个文档集合中有两个文档包含这个单词, 对应的倒排列表是{(3; 1; <4>), (5; 1; <4>)}, 这里的格式(文档编号; 在文档中出现频率; 出现位置)。 我理解如果有了某个单词在文档中出现的频率,以及包含这个单词的文档篇数, 就能算出该单词在每篇文档中的TF-IDF值, 这个值可以作为排序的一个重要指标。
5. 回到推荐领域
5.1 物料的正排信息
在推荐领域中,索引优化策略往往用在召回侧,也就是去找候选的时候。
在资源池中每条物料(新闻、商品、歌曲)都对应一个ID,物料被表示为一系列字段内容的集合。有表示标题的字段、分类的字段、地理位置的字段、价格等等,如下图所示是某一类物料资源池表的部分结构。

我们可以用每条物料唯一ID去取到这条物料的各种属性字段, 查询这条物料的详细情况,就是通常意义下的正排索引。
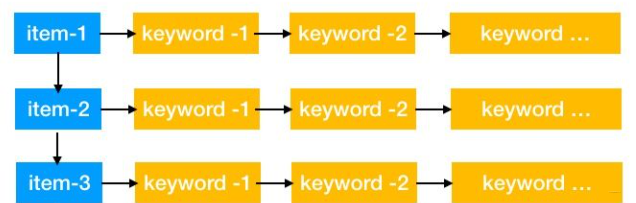
那么什么是倒排索引呢?要理解倒排索引就要理解我们的实际应用场景,在推荐系统的召回中就像前面提到的,我们实际上要取到所有某个特征、主题或关键词下的所有物料,作为推荐的候选集。这个时候就反过来了,是由以特征为出发点去找具备这些特征的物料,这就是所谓的倒排索引。

5.2 协同过滤里面的倒排思想
这也是我第一次接触倒排索引这个词的地方,就是基于用户协同过滤思想, 产生推荐列表的时候。
我们知道,用户协同过滤,是给定当前用户, 我们需要根据相似性,去找与这个用户相似的前n个用户,然后看看这n个用户点击了啥商品, 那么我们就可能推荐啥商品。
假设, 我们根据用户的行为日志,得到了四个用户A, B, C, D点击的商品情况如下:

这时候, 我们一般求用户相似性的思路就是, 外层遍历用户, 内层也遍历用户,对于内层的每个用户,看看与外层这个当前用户共同点击的商品个数,或者是保存共同点击的商品向量, 内存遍历一个用户, 就能计算一个相似度, 伪代码类似这样:
for user1, item_list1 in user_item.items():
for user2, item_list2 in user_item.items():
if user1 == user2: continue
con_click_action = 0
for item in item_list1:
if item in item_list2: # 共同点击
con_click_action += 1
# 计算当前用户相似性
similarity{user1}{user2} = con_click_action / math.sqrt(len(item_list1) * len(item_iist2)
这个在用户很多的时候是非常耗时的, 事实上, 相互之间并没有对同样的物品产生过行为, 即大部分情况下两个用户对同一物品打分的情况会很少很少, 这样遍历是很不合算的。
所以我们可以换一种倒排的思路, 建立物品到用户的倒排表, 对每个物品,都保存对该物品产生过行为的用户列表。like this:
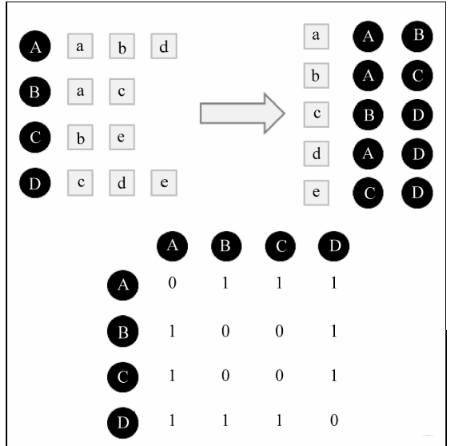
这时候, 扫描一遍倒排表, 将用户列表中两两用户对应的那个位置元素进行累加统计, 就可以得到所有用户之间同时对同一物品发生行为的次数, 也就是余弦相似度的分子。
for movie, users in movie_user.items(): # movid是movieID, users是set集合
for u in users: # 对于每个用户, 都得双层遍历
for v in users:
if u == v:
continue
user_sim_matrix.setdefault(u, {}) # 把字典的值设置为字典的形式
user_sim_matrix[u].setdefault(v, 0)
user_sim_matrix[u][v] += 1 # 这里统计两个用户对同一部电影产生行为的次数, 这个就是余弦相似度的分子
# 下面计算用户之间的相似性
for u, related_users in user_sim_matrix.items():
for v, count in related_users.items(): # 这里面v是相关用户, count是共同对同一部电影打分的次数
user_sim_matrix[u][v] = count / math.sqrt(len(trainSet[u]) * len(trainSet[v])) # len 后面的就是用户对电影产生过行为的个数
参考资料:
- 什么是倒排索引?
- 正排索引和倒排索引理解
- 推荐系统之索引的应用