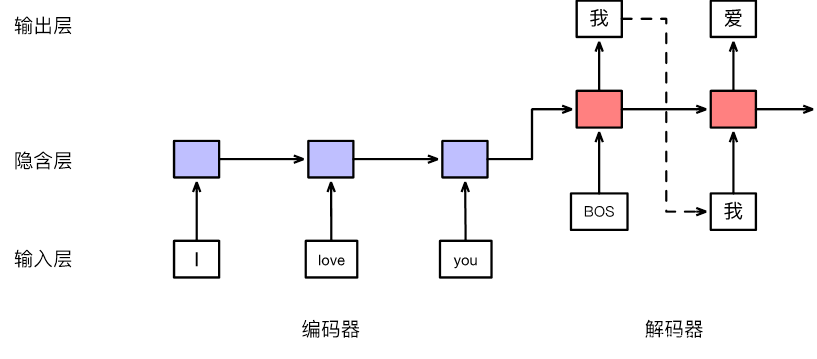
一、RNN
前馈神经网络:信息往一个方向流动。包括MLP和CNN
循环神经网络:信息循环流动,网络隐含层输出又作为自身输入,包括RNN、LSTM、GAN等。
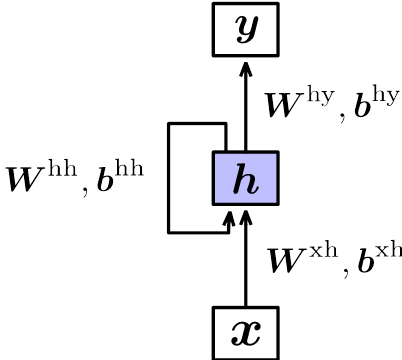
RNN模型结构如下图所示:
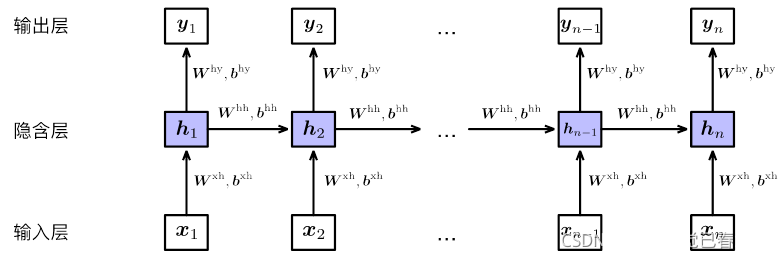
展开之后相当于堆叠多个共享隐含层参数的前馈神经网络:
其输出为:
h
t
=
t
a
n
h
(
W
x
h
x
t
+
b
x
h
+
W
h
h
h
t
−
1
+
b
h
h
)
\mathbf {h_{t}=tanh(W^{xh}x_{t}+b^{xh}+W^{hh}h_{t-1}+b^{hh})}
ht=tanh(Wxhxt+bxh+Whhht−1+bhh)
y
n
=
s
o
f
t
m
a
x
(
W
h
y
h
n
+
b
h
y
)
\mathbf {y_{n}=softmax(W^{hy}h_{n}+b^{hy})}
yn=softmax(Whyhn+bhy)
- 即隐含层输入不但与当前时刻输入 x t x_{t} xt有关,还与前一时刻隐含层 h t − 1 h_{t-1} ht−1有关。每个时刻的输入经过层层递归,对最终输入产生一定影响。
- 每个时刻隐含层 h t h_{t} ht包含1~t时刻全部输入信息,所以隐含层也叫记忆单元(Memory)
- 每个时刻参数共享(‘循环’的由来)
- 每个时刻也可以有相应的输出(序列标注)
二、长短时记忆网络LSTM
RNN的缺点是信息经过多个隐含层传递到输出层,会导致信息损失。更本质地,会造成网络参数难以优化。LSTM加入全局信息context,可以解决这一问题。
1. 跨层连接
LSTM首先将隐含层更新方式改为:
u
t
=
t
a
n
h
(
W
x
h
x
t
+
b
x
h
+
W
h
h
h
t
−
1
+
b
h
h
)
\mathbf {u_{t}=tanh(W^{xh}x_{t}+b^{xh}+W^{hh}h_{t-1}+b^{hh})}
ut=tanh(Wxhxt+bxh+Whhht−1+bhh)
h
t
=
h
t
−
1
+
u
t
\mathbf {h_{t}=h_{t-1}+u_{t}}
ht=ht−1+ut
这样可以直接将
h
k
h_{k}
hk与
h
t
h_{t}
ht相连,实现跨层连接,减小网络层数,使得网络参数更容易被优化。证明如下:
h
t
=
h
t
−
1
+
u
t
=
h
t
−
2
+
u
t
−
1
+
u
t
=
.
.
.
=
h
k
+
u
k
+
1
+
u
k
+
2
+
.
.
.
+
u
t
−
1
+
u
t
\mathbf {h_{t}=h_{t-1}+u_{t}=h_{t-2}+u_{t-1}+u_{t}=...=h_{k}+u_{k+1}+u_{k+2}+...+u_{t-1}+u_{t}}
ht=ht−1+ut=ht−2+ut−1+ut=...=hk+uk+1+uk+2+...+ut−1+ut
- 增加遗忘门 forget gate
上式直接将旧状态 h t − 1 h_{t-1} ht−1和新状态 u t u_{t} ut相加,没有考虑两种状态对 h t h_{t} ht的不同贡献。故计算 h t − 1 h_{t-1} ht−1和 u t u_{t} ut的系数,再进行加权求和
f t = σ ( W f , x h x t + b f , x h + W f , h h h t − 1 + b f , h h ) \mathbf {f_{t}=\sigma(W^{f,xh}x_{t}+b^{f,xh}+W^{f,hh}h_{t-1}+b^{f,hh})} ft=σ(Wf,xhxt+bf,xh+Wf,hhht−1+bf,hh)
h t = f t ⊙ h t − 1 + ( 1 − f t ) ⊙ u t \mathsf {h_{t}=f_{t}\odot h_{t-1}+(1-f_{t})\odot u_{t}} ht=ft⊙ht−1+(1−ft)⊙ut
其中 σ \sigma σ表示sigmoid函数,值域为(0,1)。当 f t f_{t} ft较小时,旧状态贡献也较小,甚至为0,表示遗忘不重要的信息,所以称为遗忘门。 - 增加输入门 Input gate
上一步问题是旧状态 h t − 1 h_{t-1} ht−1和新状态 u t u_{t} ut权重互斥。但是二者可能都很大或者很小。所以需要用独立的系数来调整。即:
i t = σ ( W i , x h x t + b i , x h + W i , h h h t − 1 + b i , h h ) \mathbf {i_{t}=\sigma(W^{i,xh}x_{t}+b^{i,xh}+W^{i,hh}h_{t-1}+b^{i,hh})} it=σ(Wi,xhxt+bi,xh+Wi,hhht−1+bi,hh)
h t = f t ⊙ h t − 1 + i t ⊙ u t \mathsf {h_{t}=f_{t}\odot h_{t-1}+i_{t}\odot u_{t}} ht=ft⊙ht−1+it⊙ut
i t i_{t} it用于控制输入状态 u t u_{t} ut对当前状态的贡献,所以称为输入门 - 增加输出门output gate
o t = σ ( W o , x h x t + b o , x h + W o , h h h t − 1 + b o , h h ) \mathbf {o_{t}=\sigma(W^{o,xh}x_{t}+b^{o,xh}+W^{o,hh}h_{t-1}+b^{o,hh})} ot=σ(Wo,xhxt+bo,xh+Wo,hhht−1+bo,hh) - 综合计算
u t = t a n h ( W x h x t + b x h + W h h h t − 1 + b h h ) \mathbf {u_{t}=tanh(W^{xh}x_{t}+b^{xh}+W^{hh}h_{t-1}+b^{hh})} ut=tanh(Wxhxt+bxh+Whhht−1+bhh)
f t = σ ( W f , x h x t + b f , x h + W f , h h h t − 1 + b f , h h ) \mathbf {f_{t}=\sigma(W^{f,xh}x_{t}+b^{f,xh}+W^{f,hh}h_{t-1}+b^{f,hh})} ft=σ(Wf,xhxt+bf,xh+Wf,hhht−1+bf,hh)
i t = σ ( W i , x h x t + b i , x h + W i , h h h t − 1 + b i , h h ) \mathbf {i_{t}=\sigma(W^{i,xh}x_{t}+b^{i,xh}+W^{i,hh}h_{t-1}+b^{i,hh})} it=σ(Wi,xhxt+bi,xh+Wi,hhht−1+bi,hh)
c t = f t ⊙ c t − 1 + i t ⊙ u t \mathbf {c_{t}=f_{t}\odot c_{t-1}+i_{t}\odot u_{t}} ct=ft⊙ct−1+it⊙ut
h t = o t ⊙ t a n h ( c t ) \mathbf {h_{t}=o_{t}\odot tanh(c_{t})} ht=ot⊙tanh(ct)
- 遗忘门: f t f_{t} ft,是 c t − 1 c_{t-1} ct−1的系数,可以过滤上一时刻的记忆信息
- 输入门: i t i_{t} it,是 u t u_{t} ut的系数,可以过滤当前时刻的输入信息
- 输出门: o t o_{t} ot,是 t a n h ( c t ) tanh(c_{t}) tanh(ct)的系数,控制记忆信息
- 记忆细胞: c t c_{t} ct,记录了截止当前时刻的重要信息。
可以看出RNN的输入层隐含层和输出层三层都是共享参数,到了LSTM都变成参数不共享了。
2.2 双向循环神经网络Bi-LSTM
- 解决循环神经网络信息单向流动的问题。(比如一个词的词性与前面的词有关,也与自身及后面的词有关)
- 将同一个输入序列分别接入前向和后向两个循环神经网络中,再将两个循环神经网络的隐含层结果拼接在一起,共同接入输出层进行预测。其结构如下:
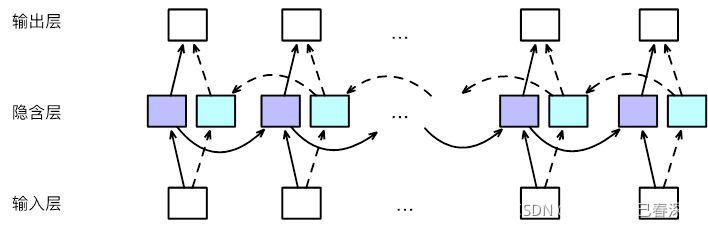
此外还可以堆叠多个双向循环神经网络。
LSTM比起RNN多了最后时刻的记忆细胞,即:
bilstm=nn.LSTM(
input_size=1024,
hidden_size=512,
batch_first=True,
num_layers=2,#堆叠层数
dropout=0.5,
bidirectional=True#双向循环)
hidden, hn = self.rnn(inputs)
#hidden是各时刻的隐含层,hn为最后时刻隐含层
hidden, (hn, cn) = self.lstm(inputs)
#hidden是各时刻的隐含层,hn, cn为最后时刻隐含层和记忆细胞
三、序列到序列模型