
学习《Neural Collaborative Filtering》。该论文介绍了利用深度神经网络去建模user-item interaction,提出了NCF框架,并实例化GMF、MLP、NeuMF。
MF出现的问题
1.假设所有隐藏因子相互独立,MF可以被看做是线性模型(在做内积时,相当于对应位置的权重都是1),仅仅是对浅层特征做处理,结果偏差较大。2.MF的隐藏因子不好确定。对于一个复杂的user-item interaction,低维的效果不好,但是对于一个稀疏矩阵,增加隐藏因子的数量变成高维可能会造成overfit。
NCF框架
作者就利用DNNs构建了NCF框架,对user-item interaction进行建模,利用多层神经网络得出预测值y^ui。
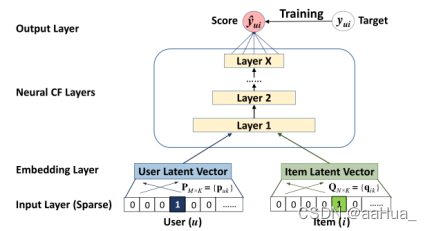
因为是利用隐性数据(1表示交互过,0表示未交互)测试,所以在输出层加上概率函数(sigmoid)的激活函数。因此优化:SGD—log loss。
NeuMF
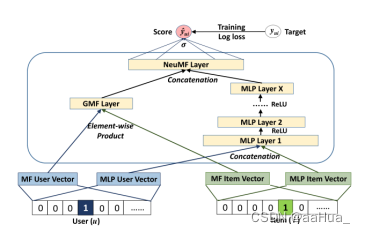
左侧GMF,右侧MLP,集成为NeuMF。
GMF:MF可以被解释在NCF框架下的一种特殊形式(还是一种线性结构)。如下,公式为: y^ui = aout (hT(pu⨀qi)) 令aout 为恒等函数,h向量都是1,这就是典型的MF。
MLP:NCF框架是把用户特征向量和物品特征向量结合起来,如果简单的把向量拼接起来不能说明用户和物品隐特征之间的任何交互。所以引出MLP进行提取物品和用户之间的交互信息。MLP层的Action function选取Relu(sigmoid限制到(0,1),tanh是sigmoid的拓展版本)。
初始化时,可以先利用Adam优化对GMF和MLP预训练,预训练的参数作为NeuMF的初始化,NeuMF利用SGD进行优化。
NeuMF模型结合了GMF的线性和MLP的非线性去建模user-item interaction。
Dataset: MovieLens;Pinterest
BaseLInes:ItemPop、ItemKNN、BPR、eALS
LFM和NCF区别:
1.LFM将user-item matrix分解成用户和物品的隐性矩阵,NCF是构建了一个user-item interaction模型。
2.LFM只能考虑隐性类之间的线性关系(对于隐性因子较少时,通常是非线性关系)。NCF对于线性关系可以实例化GMF,如果有非线性关系可以把MLP也集成进来。
3.LFM只能补全user-item matrix,存在新用户和新物品的冷启动问题。而NCF泛化能力强,通用性强,可以处理新用户或新物品,因为模型中有一个embedding layer,可以训练映射层中的参数,这样就会映射新用户或者新物品到一个隐特征向量中。
代码实现效果:
对比实验组:
参数设置:
dataset: MovieLens;Pinterest
batch_size = 256
topK = 10
lr = 0.001
epochs = 10 (论文作者设置的100,由于学习模型就没跑这么多)
factors = 8/16/32
layers_num(MLP层数) = 3
GMF、MLP、NeuMF优化器:Adam
GMF、MLP、NeuMF损失函数:BCELoss()
每组评估指标:
HR:关心用户想要的,我有没有推荐到,强调预测的“准确性”
NDCG:关心找到的这些项目,是否放在用户更显眼的位置里,即强调“顺序性“
在MovieLens数据集上(训练集4970845条数据,验证集6040条数据):
1. factors = 8 : GMF、MLP、NeuMF_pre、NreMF_unPre
2. factors = 16:GMF、MLP、NeuMF_pre、NreMF_unPre
3. 在GMF上:factors = 8 、16 、32
4. 在MLP上:factors = 8 、16 ( MLP训练时间比较长,没有测factors=32)
5. 在NeuMF_pre:factors = 8 、16 (由于MLP的factors=32没测,所以NeuMF初始化参数没有)
6. 在NeuMF_unpre:factors = 8 、16 (由于MLP的factors=32没测,所以NeuMF初始化参数没有)
在Pinterest数据集上(训练集7041970条数据,验证集55187条数据):
1. factors = 8 : GMF、MLP、NeuMF_pre
在我的电脑中10次epochs差不多跑30-40分钟。
在MovieLens数据集上:
-
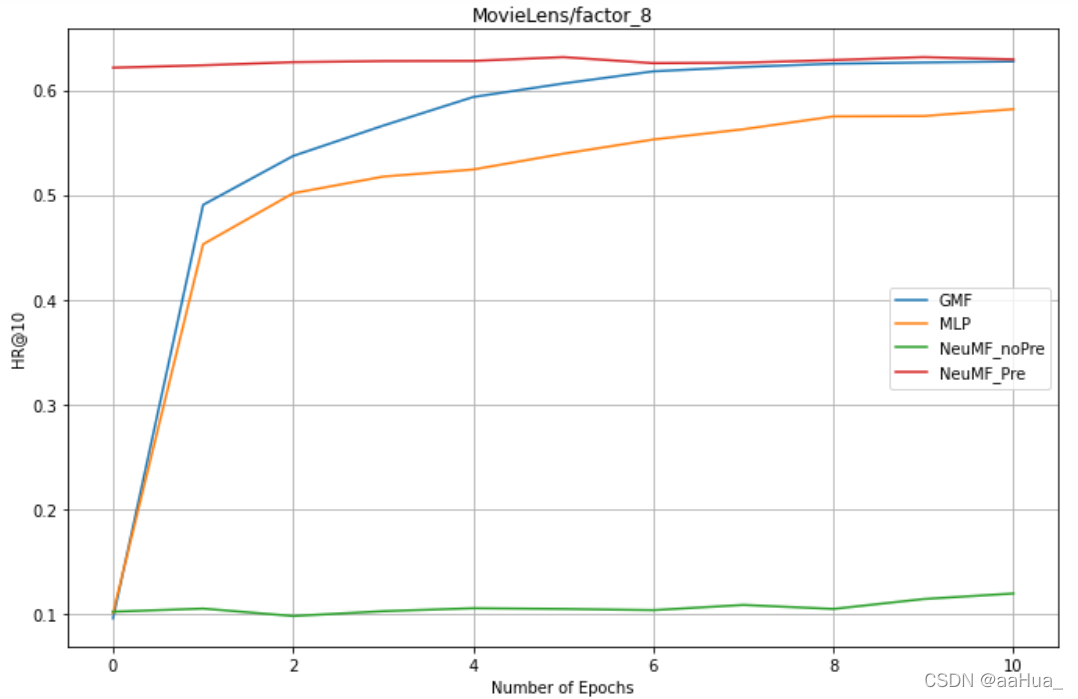
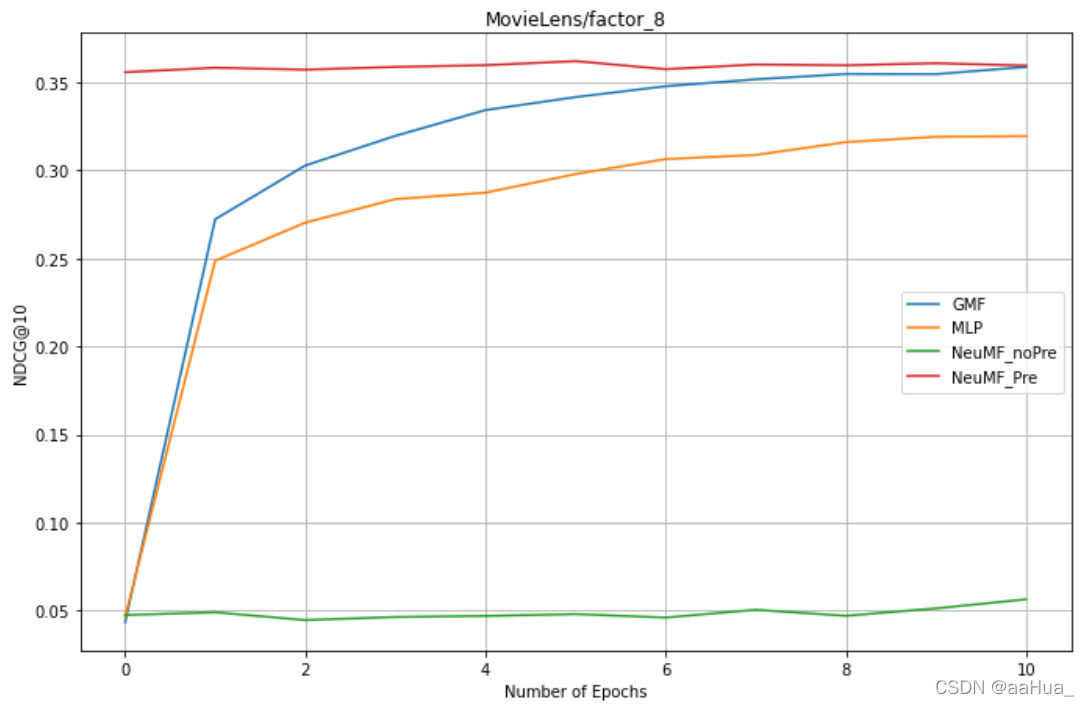
factors = 8 : GMF、MLP、NeuMF_pre、NreMF_unPre
-
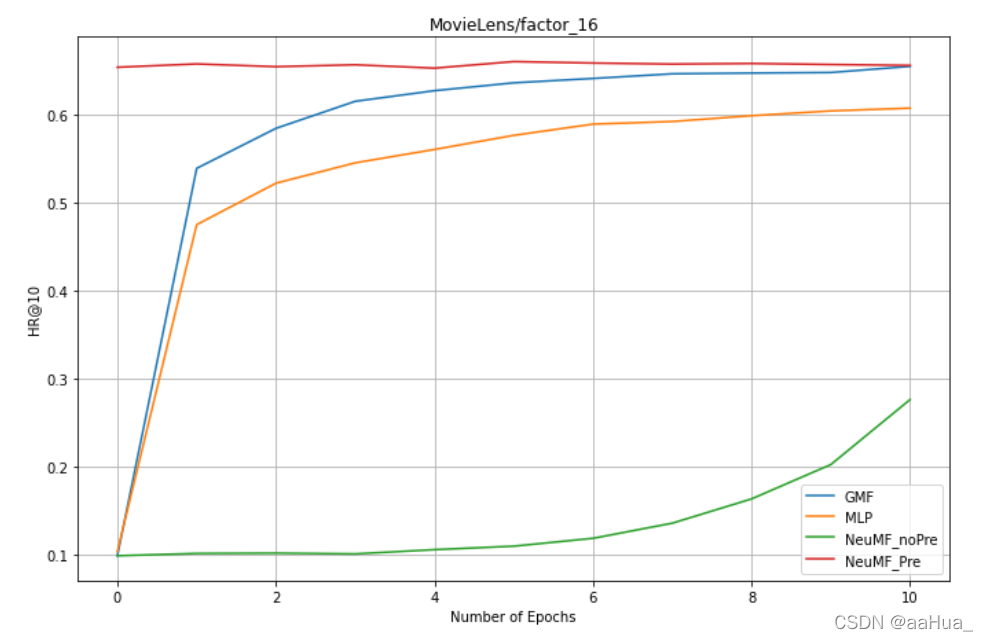
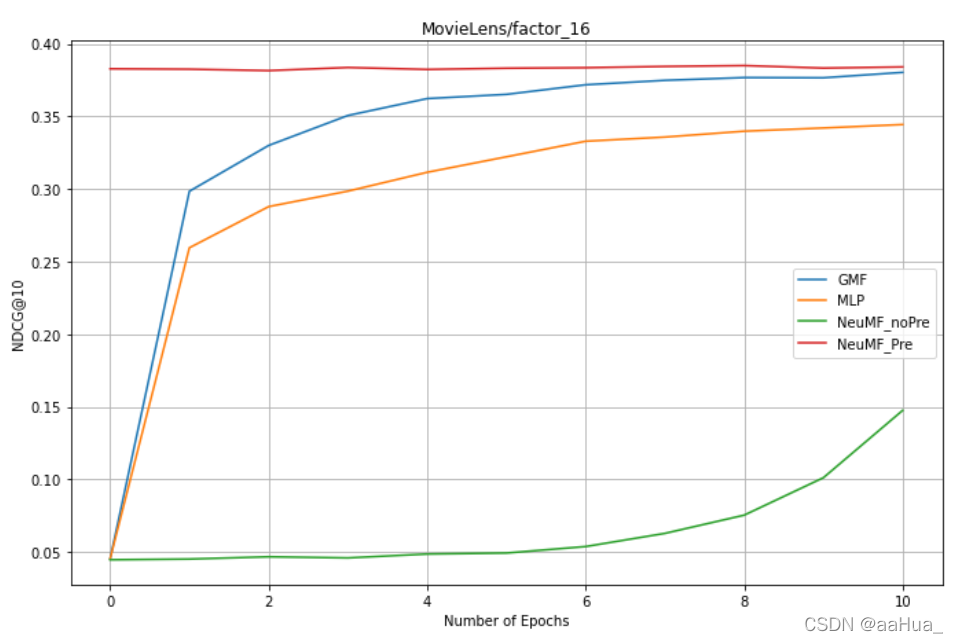
factors = 16:GMF、MLP、NeuMF_pre、NreMF_unPre
-
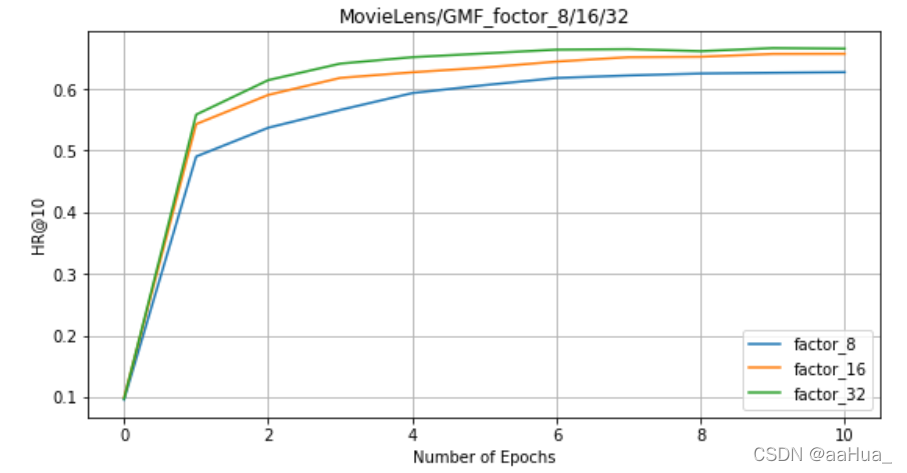
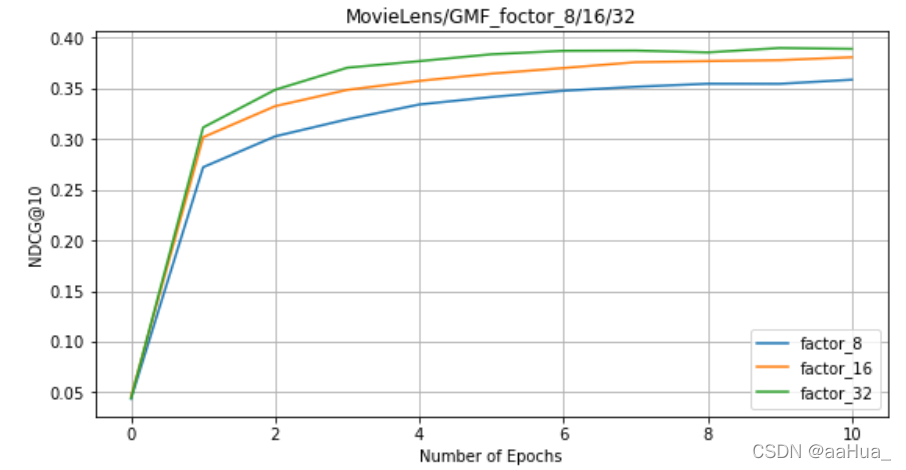
在GMF上:factors = 8 、16 、32
-
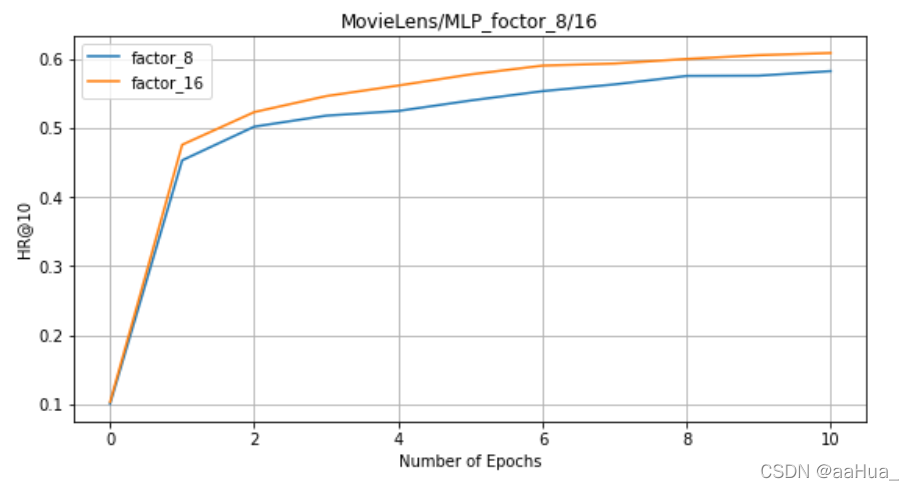
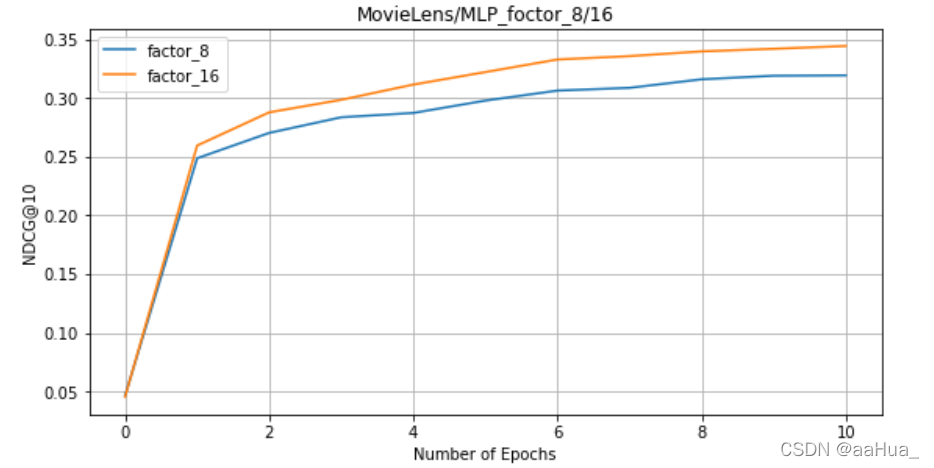
在MLP上:factors = 8 、16 ( MLP训练时间比较长,没有测factors=32)
-
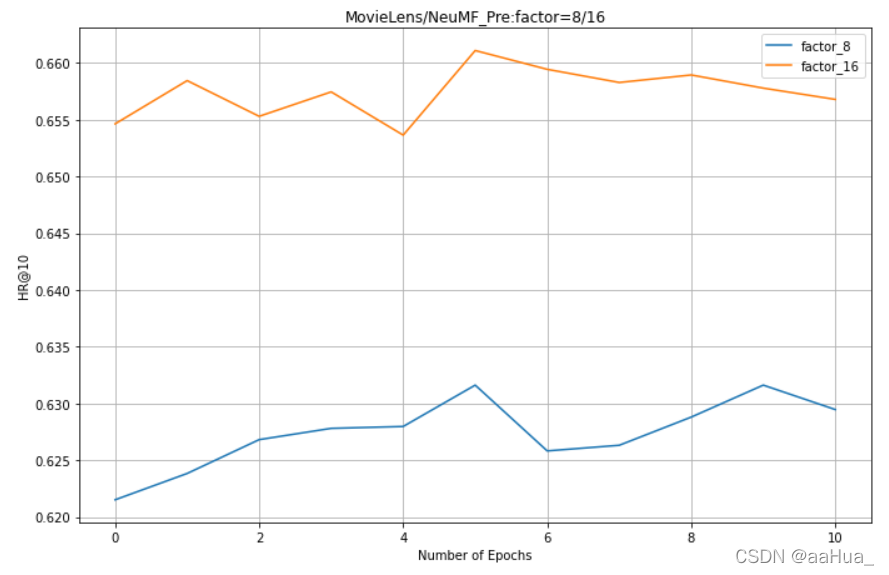
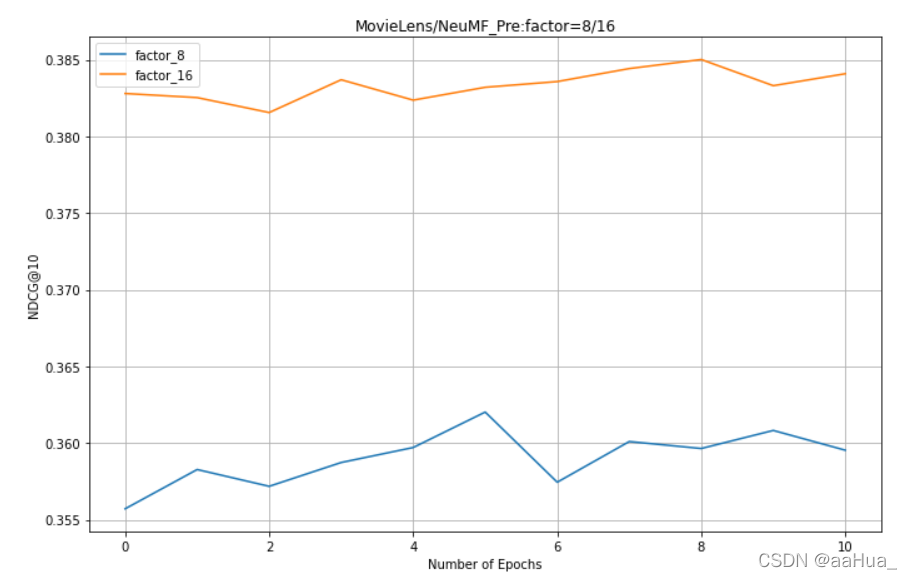
在NeuMF_pre:factors = 8 、16 (由于MLP的factors=32没测,所以NeuMF初始化参数没有)
-
在NeuMF_unpre:factors = 8 、16 (由于MLP的factors=32没测,所以NeuMF初始化参数没有)
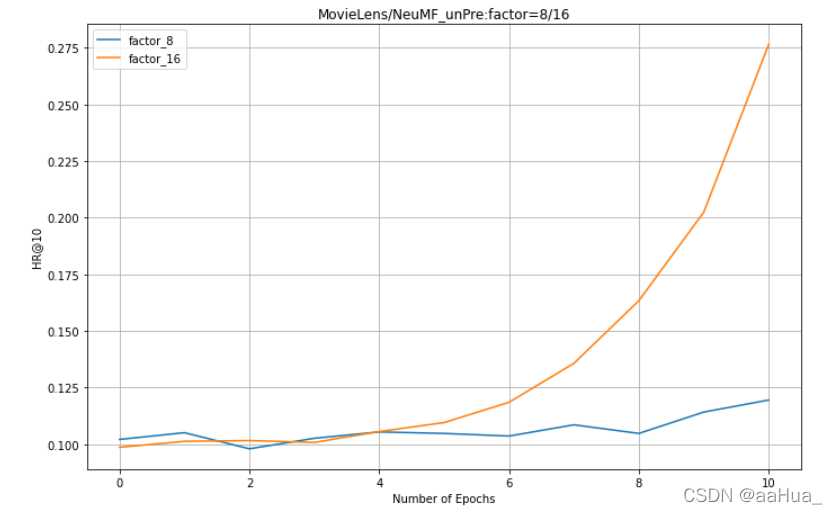
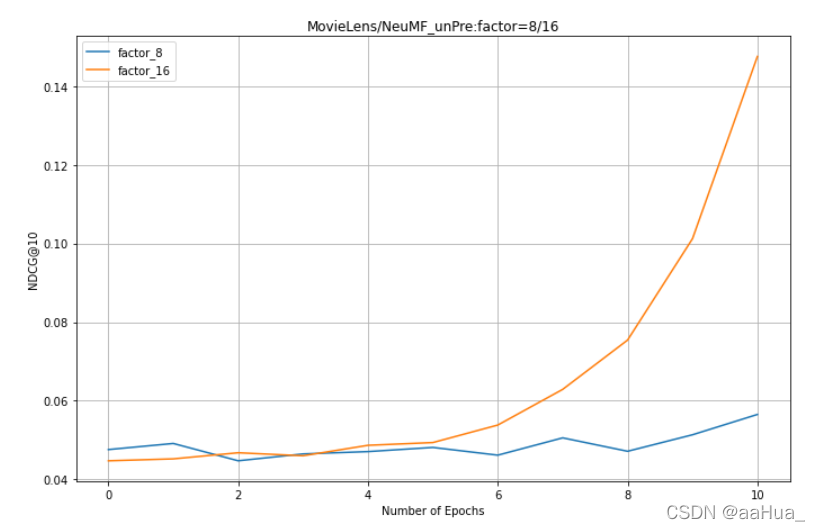
在Pinterest数据集上:
1. factors = 8 : GMF、MLP、NeuMF_pre
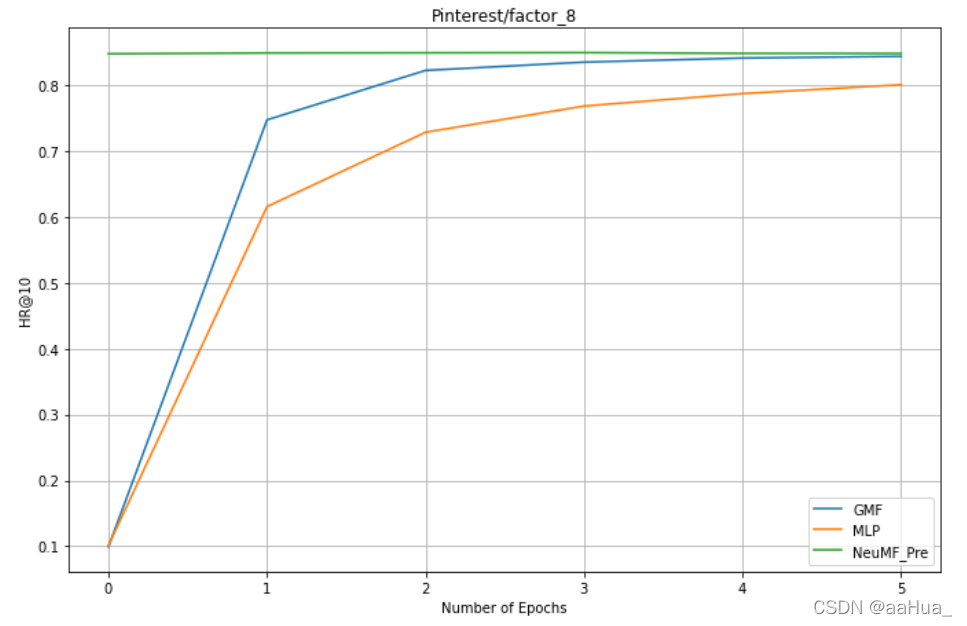
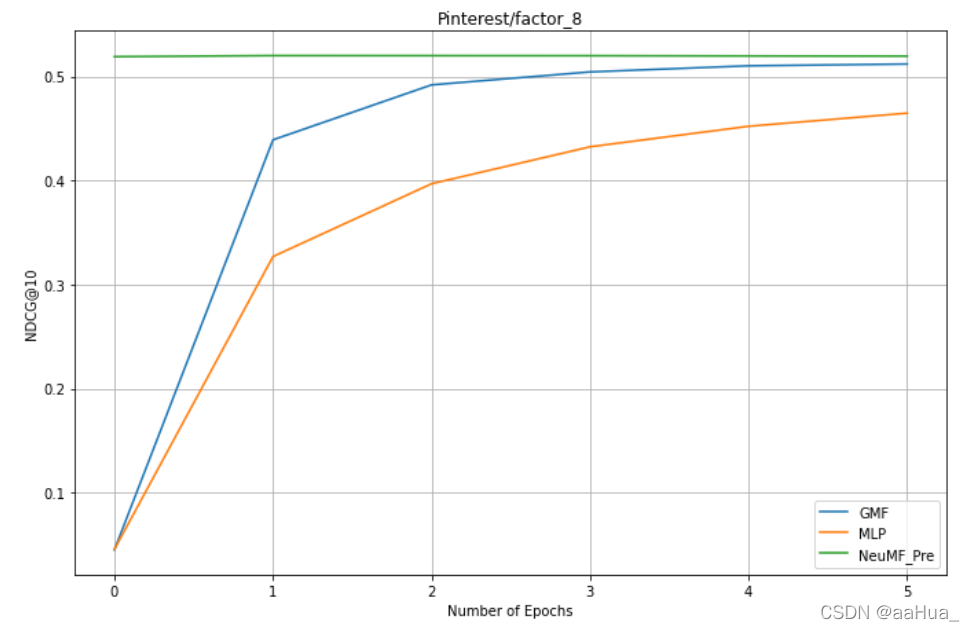
结论:
1.预训练的NeuMF效果优于GMF和MLP(结合了线性GMF和非线性MLP)
2.没有预训练的NeuMF需要更多的epochs才可以得到好的效果。
3.GMF效果优于MLP
4.数据集越大(Pinterest是MovieLens数据集的近两倍),效果越好。
5.对于NeuMF、GMF、MLP,factor是越大,效果越好。
主要代码:
加载数据集:
def load_data():
#train_mat
train_data = pd.read_csv('Data/ml-1m.train.rating',sep='\t',header=None,
names=['user','item'],usecols=[0,1],dtype={0: np.int32, 1: np.int32})
user_num = train_data['user'].max() + 1
item_num = train_data['item'].max() + 1
train_data = list(train_data.values)
train_mat = sp.dok_matrix((user_num,item_num),dtype=np.float32)
for x in train_data:
train_mat[x[0],x[1]] = 1.0
#testRatings
ratingList = []
with open('Data/ml-1m.test.rating', "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
user, item = int(arr[0]), int(arr[1])
ratingList.append([user, item])
line = f.readline()
#testNegatives
negativeList = []
with open('Data/ml-1m.test.negative', "r") as f:
line = f.readline()
while line != None and line != "":
arr = line.split("\t")
negatives = []
for x in arr[1: ]:
negatives.append(int(x))
negativeList.append(negatives)
line = f.readline()
return train_mat, ratingList, negativeList
train_mat, testRatings, testNegatives = load_data()
user_num, item_num = train_mat.shape
train_mat, testRatings, testNegatives = load_data()
train_mat是训练矩阵,还需要负采样;testRatings, testNegatives是我们评估指标时用到的两个list,testRatings是评估样本,testNegatives看testRatings是否出现(HR),出现在哪个位置(NDCG)。
负采样:
def get_train_instances(train, num_negatives = 4, num_item = item_num):
user_input, item_input, labels = [], [], []
for (u,i) in train.keys():
#positive instance
user_input.append(u)
item_input.append(i)
labels.append(1)
#negative instance
for t in range(num_negatives):
j = np.random.randint(num_item)
while u in train.keys() and j in train:
j = np.random.randint(num_item)
user_input.append(u)
item_input.append(j)
labels.append(0)
return user_input,item_input,labels
user_num, item_num = train_mat.shape
#加载负采样后的结果
user_input,item_input,labels = get_train_instances(train_mat)
#矩阵转Tensor,注意输入Embeding层必须LongTensor
user_input = np.array(user_input)
user_input = torch.LongTensor(user_input)
item_input = np.array(item_input)
item_input = torch.LongTensor(item_input)
labels = np.array(labels)
labels = torch.FloatTensor(labels)
user_input = user_input.reshape(-1,1)
item_input = item_input.reshape(-1,1)
labels = labels.reshape(-1,1)
#为了分割数据,concat起来
train_Data = torch.cat((user_input,item_input),1)
train_Data = torch.cat((train_Data,labels),1)
#batch_size = 256,data_train就是训练集
data_train = Data.DataLoader(dataset = train_Data, batch_size = 256, shuffle = True)
评估指标:HR、NDCG
_model = None
_testRatings = None
_testNegatives = None
_K = None
def evaluate_model(model, testRatings, testNegatives, K, num_thread):
"""
HR、NDCG
"""
global _model
global _testRatings
global _testNegatives
global _K
_model = model
_testRatings = testRatings
_testNegatives = testNegatives
_K = K
hits, ndcgs = [],[]
for idx in range(len(_testRatings)):
(hr,ndcg) = eval_one_rating(idx)
hits.append(hr)
ndcgs.append(ndcg)
return (hits, ndcgs)
def eval_one_rating(idx):
rating = _testRatings[idx]
items = _testNegatives[idx]
u = rating[0]
gtItem = rating[1]
items.append(gtItem)
# Get prediction scores
map_item_score = {}
users = np.full(len(items), u, dtype = "int64")#用u填充一个长度为len(items)
predictions = _model.forward(torch.LongTensor(users), torch.LongTensor(np.array(items)))
for i in range(len(items)):
item = items[i]
map_item_score[item] = predictions[i]
items.pop()
# Evaluate top rank list
ranklist = heapq.nlargest(_K, map_item_score, key=map_item_score.get)#找出最大的10个数
hr = getHitRatio(ranklist, gtItem)
ndcg = getNDCG(ranklist, gtItem)
return (hr, ndcg)
def getHitRatio(ranklist, gtItem):
for item in ranklist:
if item == gtItem:
return 1
return 0
def getNDCG(ranklist, gtItem):
for i in range(len(ranklist)):
item = ranklist[i]
if item == gtItem:
return math.log(2) / math.log(i+2)#防止分母为0
return 0
HR = []
NDCG = []
(hits, ndcgs) = evaluate_model(GMF_model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
HR.append(hr)
NDCG.append(ndcg)
GMF模型:
class GMF(nn.Module):
def __init__(self, user_num, item_num, factor_num):
super(GMF, self).__init__()
"""user_num:用户数 item_num:物品数 factor_num:映射维度 """
self.embed_user_GMF = nn.Embedding(num_embeddings = user_num,embedding_dim = factor_num,norm_type=2)
self.embed_item_GMF = nn.Embedding(item_num,factor_num)
self.predict_layer = nn.Linear(factor_num, 1)
self._init_weight_()
def _init_weight_(self):
#从给定均值和标准差的正态分布N(mean, std)中生成值,填充输入的张量或变量
nn.init.normal_(self.embed_user_GMF.weight,std=0.01)
nn.init.normal_(self.embed_item_GMF.weight,std=0.01)
def forward(self, user, item):
embed_user_GMF = self.embed_user_GMF(user)
embed_item_GMF = self.embed_item_GMF(item)
#inner product
output_GMF = embed_user_GMF * embed_item_GMF
prediction = torch.sigmoid(self.predict_layer(output_GMF))
return prediction.view(-1)
MLP模型:
class MLP(nn.Module):
def __init__(self, user_num, item_num, factor_num, num_layers, dropout):
super(MLP, self).__init__()
self.embed_user_MLP = nn.Embedding(user_num, factor_num * (2 ** (num_layers - 1)))
self.embed_item_MLP = nn.Embedding(item_num, factor_num * (2 ** (num_layers - 1)))
MLP_modules = []
for i in range(num_layers):
input_size = factor_num * (2 ** (num_layers - i))
MLP_modules.append(nn.Dropout(p=dropout))
MLP_modules.append(nn.Linear(input_size, input_size//2))
MLP_modules.append(nn.ReLU())
self.MLP_layers = nn.Sequential(*MLP_modules)
self.predict_layer = nn.Linear(factor_num, 1)
self._init_weight_()
def _init_weight_(self):
nn.init.normal_(self.embed_user_MLP.weight, std=0.01)
nn.init.normal_(self.embed_item_MLP.weight, std=0.01)
for m in self.MLP_layers:
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.kaiming_uniform_(self.predict_layer.weight,a=1, nonlinearity='sigmoid')
def forward(self, user, item):
embed_user_MLP = self.embed_user_MLP(user)
embed_item_MLP = self.embed_item_MLP(item)
interaction = torch.cat((embed_user_MLP, embed_item_MLP), -1)
output_MLP = self.MLP_layers(interaction)
prediction =torch.sigmoid(self.predict_layer(output_MLP))
return prediction.view(-1)
NeuMF模型:
class NeuMF(nn.Module):
def __init__(self, user_num, item_num, factor_num, num_layers,
dropout, model, GMF_model=None, MLP_model=None):
super(NeuMF, self).__init__()
"""
user_num: number of users;
item_num: number of items;
factor_num: number of predictive factors;
num_layers: the number of layers in MLP model;
dropout: dropout rate between fully connected layers;
model: 'MLP', 'GMF', 'NeuMF-end', and 'NeuMF-pre';
GMF_model: pre-trained GMF weights;
MLP_model: pre-trained MLP weights.
"""
self.dropout = dropout
self.model = model
self.GMF_model = GMF_model
self.MLP_model = MLP_model
self.embed_user_GMF = nn.Embedding(user_num, factor_num)
self.embed_item_GMF = nn.Embedding(item_num, factor_num)
self.embed_user_MLP = nn.Embedding(
user_num, factor_num * (2 ** (num_layers - 1)))
self.embed_item_MLP = nn.Embedding(
item_num, factor_num * (2 ** (num_layers - 1)))
MLP_modules = []
for i in range(num_layers):
input_size = factor_num * (2 ** (num_layers - i))
MLP_modules.append(nn.Dropout(p=self.dropout))
MLP_modules.append(nn.Linear(input_size, input_size//2))
MLP_modules.append(nn.ReLU())
self.MLP_layers = nn.Sequential(*MLP_modules)
if self.model in ['MLP', 'GMF']:
predict_size = factor_num
else:
predict_size = factor_num * 2
self.predict_layer = nn.Linear(predict_size, 1)
self._init_weight_()
def _init_weight_(self):
""" We leave the weights initialization here. """
if not self.model == 'NeuMF-pre':
nn.init.normal_(self.embed_user_GMF.weight, std=0.01)
nn.init.normal_(self.embed_user_MLP.weight, std=0.01)
nn.init.normal_(self.embed_item_GMF.weight, std=0.01)
nn.init.normal_(self.embed_item_MLP.weight, std=0.01)
for m in self.MLP_layers:
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.kaiming_uniform_(self.predict_layer.weight,
a=1, nonlinearity='sigmoid')
for m in self.modules():
if isinstance(m, nn.Linear) and m.bias is not None:
m.bias.data.zero_()
else:
# embedding layers
self.embed_user_GMF.weight.data.copy_(
self.GMF_model.embed_user_GMF.weight)
self.embed_item_GMF.weight.data.copy_(
self.GMF_model.embed_item_GMF.weight)
self.embed_user_MLP.weight.data.copy_(
self.MLP_model.embed_user_MLP.weight)
self.embed_item_MLP.weight.data.copy_(
self.MLP_model.embed_item_MLP.weight)
# mlp layers
for (m1, m2) in zip(
self.MLP_layers, self.MLP_model.MLP_layers):
if isinstance(m1, nn.Linear) and isinstance(m2, nn.Linear):
m1.weight.data.copy_(m2.weight)
m1.bias.data.copy_(m2.bias)
# predict layers
predict_weight = torch.cat([
self.GMF_model.predict_layer.weight,
self.MLP_model.predict_layer.weight], dim=1)
precit_bias = self.GMF_model.predict_layer.bias + \
self.MLP_model.predict_layer.bias
self.predict_layer.weight.data.copy_(0.5 * predict_weight)
self.predict_layer.bias.data.copy_(0.5 * precit_bias)
def forward(self, user, item):
if not self.model == 'MLP':
embed_user_GMF = self.embed_user_GMF(user)
embed_item_GMF = self.embed_item_GMF(item)
output_GMF = embed_user_GMF * embed_item_GMF
if not self.model == 'GMF':
embed_user_MLP = self.embed_user_MLP(user)
embed_item_MLP = self.embed_item_MLP(item)
interaction = torch.cat((embed_user_MLP, embed_item_MLP), -1)
output_MLP = self.MLP_layers(interaction)
if self.model == 'GMF':
concat = output_GMF
elif self.model == 'MLP':
concat = output_MLP
else:
concat = torch.cat((output_GMF, output_MLP), -1)
prediction = torch.sigmoid(self.predict_layer(concat))
return prediction.view(-1)
训练:以GMF为例,其他同
GMF_model = GMF(user_num = user_num,item_num = item_num,factor_num = 8)
lr = 0.001
epochs = 10
topK = 10
evaluation_threads = 1
Adam_optimizer = torch.optim.Adam(GMF_model.parameters(), lr )
loss_list = []
s = time.time()
for epoch in range(epochs):
for i,data in enumerate(data_train):
user_data = data[:,0].reshape(1,-1).long()#因为我们之前把训练集拼起来了,
item_data = data[:,1].reshape(1,-1).long()#所以我们这里需要拆开
label = data[:,2]
Adam_optimizer.zero_grad()
predict = GMF_model(user_data,item_data)
loss_func = nn.BCELoss()
#loss_func = nn.MSELoss()
loss = loss_func(predict,label)
loss.backward()
Adam_optimizer.step()
loss_list.append(loss)
(hits, ndcgs) = evaluate_model(GMF_model, testRatings, testNegatives, topK, evaluation_threads)
hr, ndcg = np.array(hits).mean(), np.array(ndcgs).mean()
HR.append(hr)
NDCG.append(ndcg)
print(loss_list[-1])
print(HR)
print(NDCG)
e = time.time()
print(e-s)
存模型:
torch.save(GMF_model,'GMF_model.pkl')
取模型
GMF_model = torch.load("GMF_model.pkl")
存数据:
torch.save(HR,'P_GMF_8_hr')
取数据:
data = torch.load("P_GMF_8_hr")
论文源码地址:何向南老师