
前言:我们来了解一下http2.0,http2.0是为了加快网页渲染速度所发布的新的协议,我们之前使用的request只能够get请求到http1.0的数据而http2.0就没有办法了,所以为了爬取http2.0的数据,我们需要了解一个第三方库hyper来帮助我们获取数据,有了hyperlpr库在手,抓取数据简直轻轻松松。hyper使用文档
http协议版本在这里查看
1.安装hyperlpr库
pip install hyper -i https://pypi.douban.com/simple/
2.分析过程
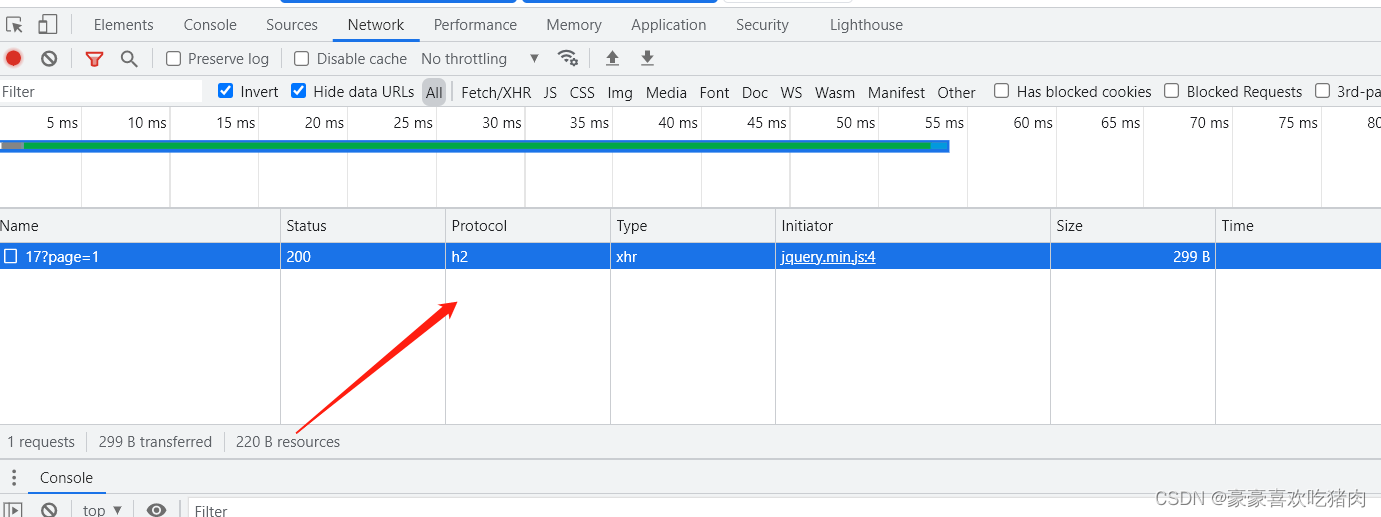
通过使用chrome浏览器的f12调试工具抓包,获取数据包的url
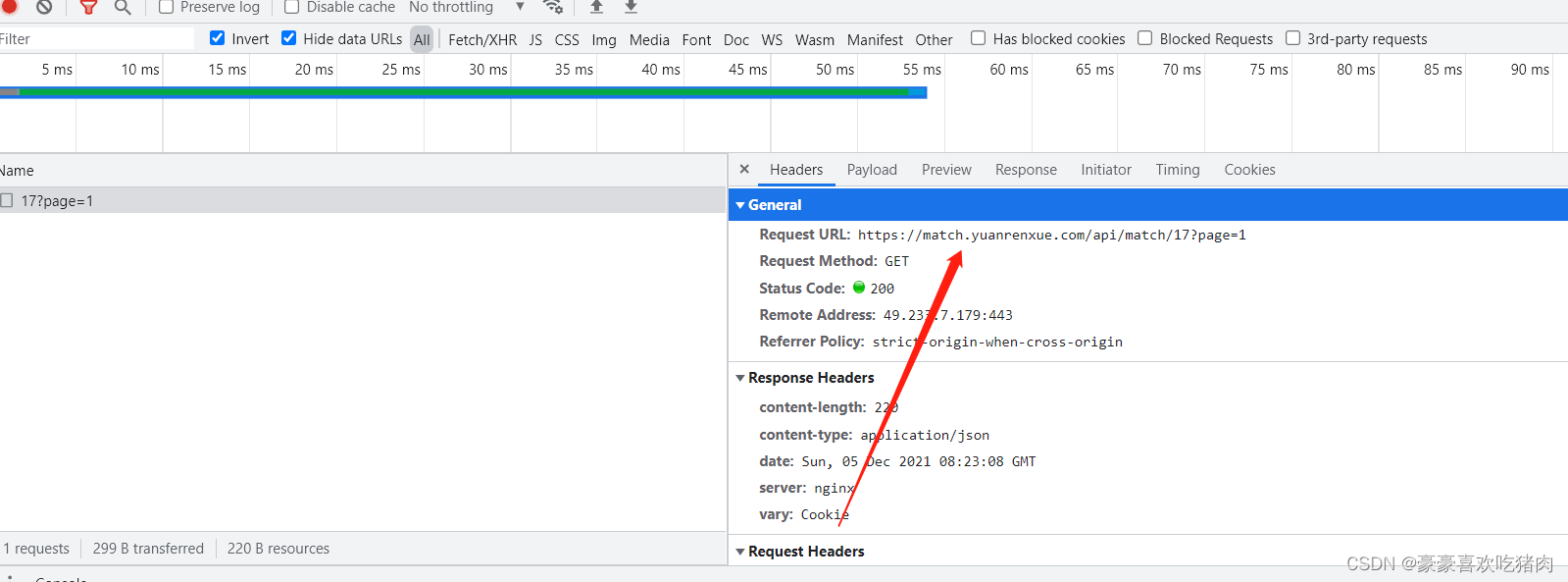
除了http2.0之外,基本没有其他的反爬手段,我们直接上代码:
3.代码
import jsonpath
import requests
from hyper.contrib import HTTP20Adapter
if __name__ == '__main__':
url_ = 'https://match.yuanrenxue.com/api/match/17?page={}'
headers_ = {
"User-Agent": "yuanrenxue.project",
# 设置我们登陆账号时候的cookie一边一会请求时服务器返回我们对应的sessionid
"cookie":"这里输入你自己的cookie";
}
# 创建session对象,并设置请求头
s = requests.session()
s.headers = headers_
# 使用http2.0
s.mount('https://match.yuanrenxue.com', HTTP20Adapter())
num = 0
for i in range(5):
# 发送请求
json_data = s.get(url_.format(i + 1)).json()
# 提取数据
num_list = jsonpath.jsonpath(json_data, '$..value')
for j in num_list:
print(j, end='\t')
num += j
print()
print('num:', num)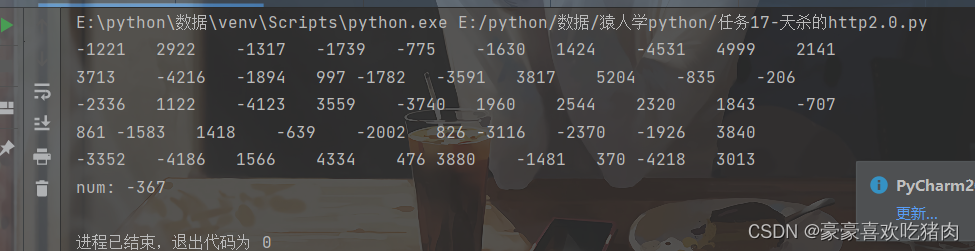
结束