Pandas操作入门
索引
创建&增加
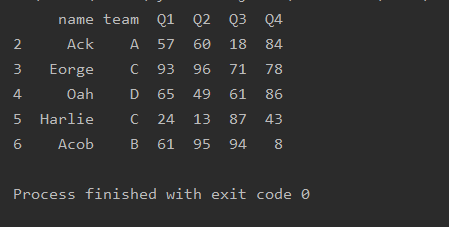
方法一:
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df)
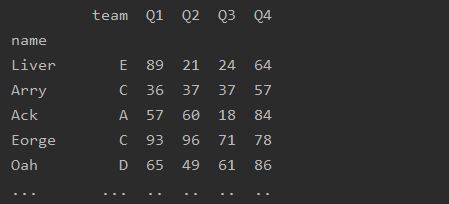
方法二:
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name')
print(df)
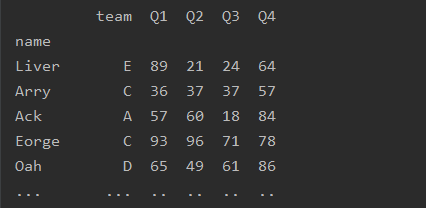
多层索引
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index(['name','team'])
print(df)
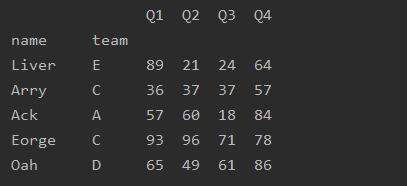
不删除设置的索引列、
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name',drop=False)
print(df)
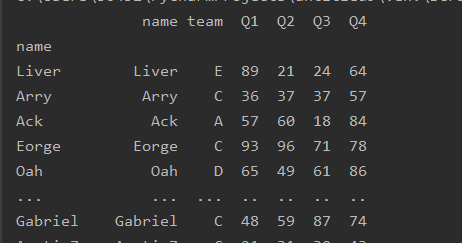
增加索引(保留原索引)
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name',append=True)
print(df)
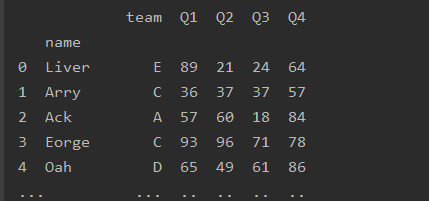
删除(还原)
默认删除所有级别索引
df=pd.read_excel('text.xlsx')
df=df.set_index('name')
print(df)
df=df.reset_index()
# 指定索引列
# df=df.reset_index(level=0)
# df=df.reset_index(level='name')
print(df)
name从索引变成了列
注意:
如果在设置索引时 设置不删除设置的索引列 运行将会报错
提示数据已存在
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name',drop=False)
print(df)
df=df.reset_index()
print(df)

属性
import pandas as pd
df=pd.read_excel('text.xlsx')
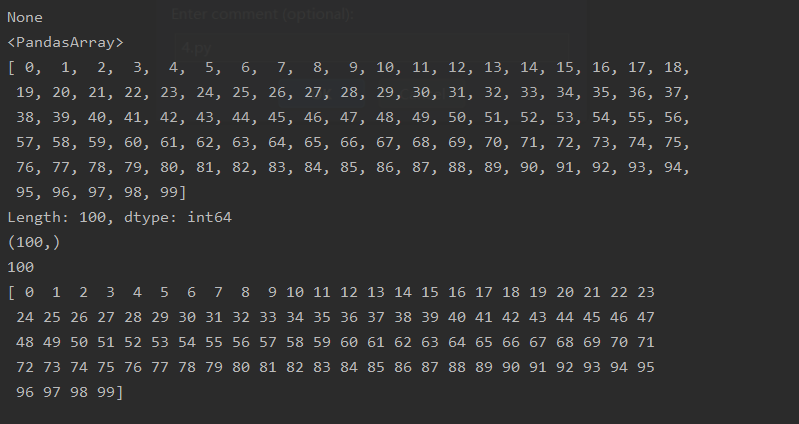
# 名称
print(df.index.name)
# array数组
print(df.index.array)
# 数据类型
print(df.index.dtype)
# 元素数量
print(df.index.size)
# array数组
print(df.index.values)
常用操作
df.index.astype('int64') # 转换类型
df.index.isin() # 检查是否存在
df.index.rename('number') # 修改索引名称
df.index.rename(['name', 'team']) # 多层,重命名索引
df.index.nunique() # 不重复值的数量
df.index.sort_values(ascending=False,) # 排序,倒序
df.index.map(lambda x:x+'_') # map函数处理
df.index.str.replace('_', '') # str替换
df.index.str.split('_') # 分隔
df.index.to_list() # 转为列表
df.index.to_frame(index=False, name='a') # 转成DataFrame
df.index.to_series() # 转为series
df.index.to_numpy() # 转为numpy
df.index.unique() # 去重
df.index.value_counts() # 去重及计数
df.index.where(df.index=='adf') # 筛选
df.index.max() # 最大值
df.index.argmax() # 最大索引值
df.index.min() # 最大值
df.index.argmin() # 最大索引值
df.index.T # 转置
重命名
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name')
print(df)
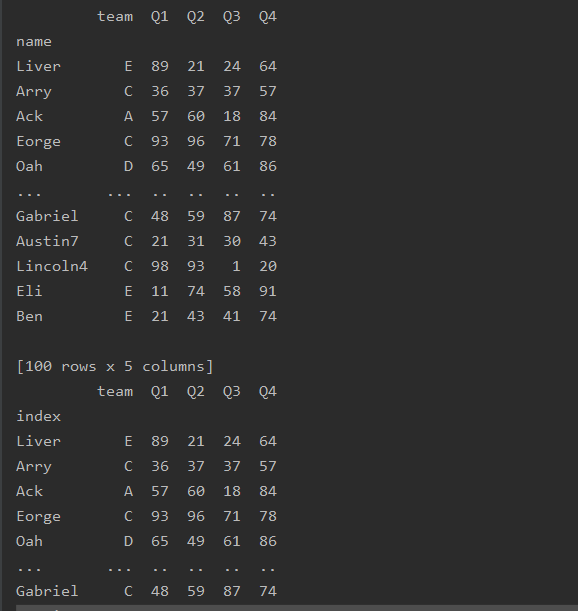
df=df.rename_axis('index')
print(df)
修改多层索引名
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index(['name','team'])
print(df)
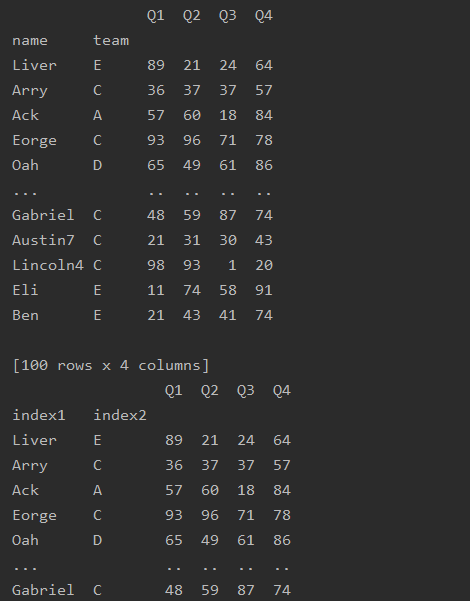
df=df.rename_axis(['index1','index2'])
print(df)
修改索引内容
修改列名
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name')
print(df)
# 一对一修改
df=df.rename(columns={'team':'0'})
print(df)
# 修改全部
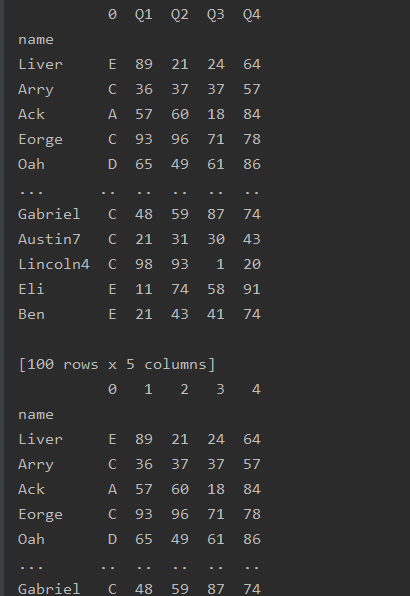
df=df.set_axis(['0','1','2','3','4'],axis=1)
print(df)
修改索引
import pandas as pd
df=pd.read_excel('text.xlsx')
df=df.set_index('name')
print(df)
# 一对一修改
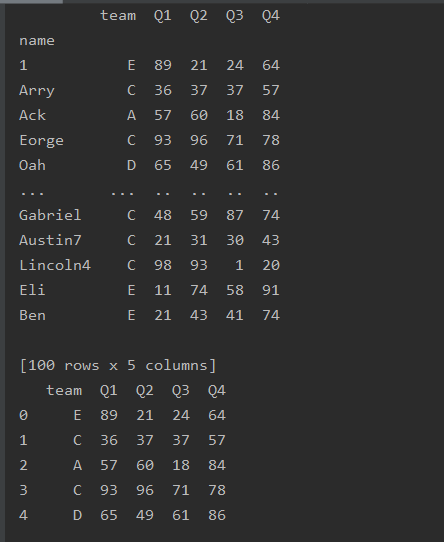
df=df.rename(index={'Liver':'1'})
print(df)
# 修改全部
df=df.set_axis(list(range(0,100)),axis='index')
print(df)
数据
样式查看
import pandas as pd
df=pd.read_excel('text.xlsx')
# 查看前面数据 默认5条
print(df.head())
# 查看后面数据 默认5条
print(df.tail())
# 随机查看数据 默认1条
print(df.sample())
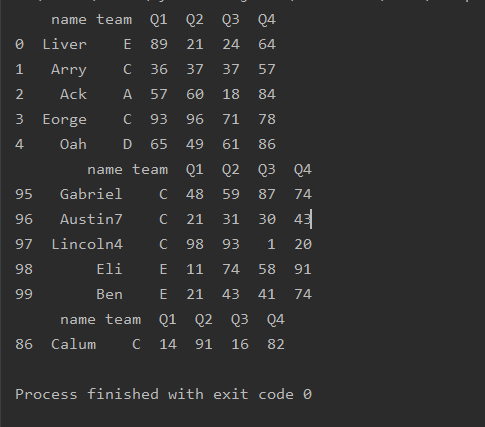
指定条数
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.head(2))
print(df.tail(2))
print(df.sample(2))
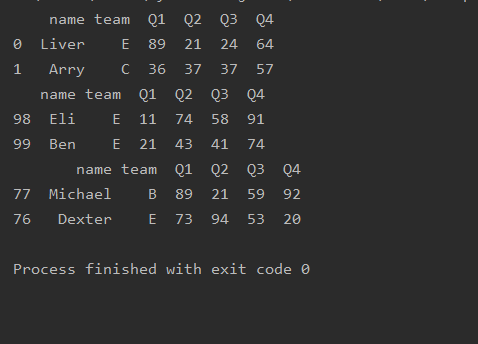
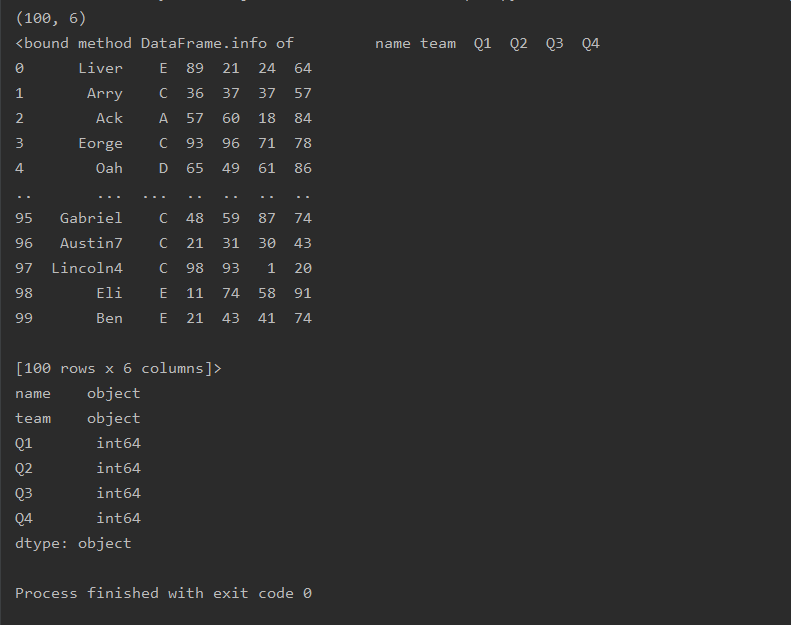
属性
import pandas as pd
df=pd.read_excel('text.xlsx')
# 维度
print(df.shape)
# 信息
print(df.info)
# 数据类型
print(df.dtypes)
数据统计或处理
统计表
总数、平均数、标准差、最小值、四分位数、最大值
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.describe())
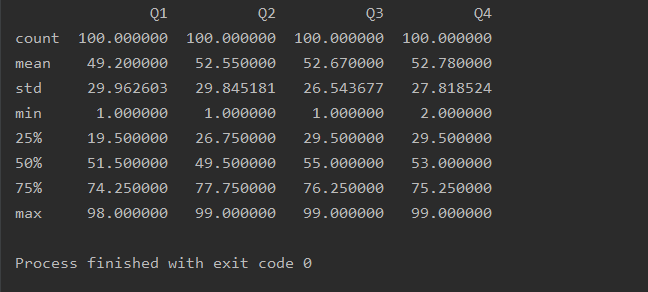
函数
df.mean() # 返回所有列的均值
df.corr() # 返回列与列之间的相关系数
df.count() # 返回每一列中的非空值的个数
df.max() # 返回每一列的最大值
df.min() # 返回每一列的最小值
df.abs() # 绝对值
df.median() # 返回每一列的中位数
df.std() # 返回每一列的标准差,贝塞尔校正的样本标准偏差
df.var() # 无偏方差
df.sem() # 平均值的标准误差
df.mode() # 众数
df.prod() # 连乘
df.mad() # 平均绝对偏差
df.cumprod() # 累积连乘,累乘
df.cumsum(axis=0) # 累积连加,累加
df.nunique() # 去重数量,不同值的量
df.idxmax() # 每列最大值的索引名
df.idxmin() # 每列最小值的索引名
df.cummax() # 累积最大值
df.cummin() # 累积最小值
df.skew() # 样本偏度(第三阶)
df.kurt() # 样本峰度(第四阶)
df.quantile() # 样本分位数(不同 % 的值)
指定单列
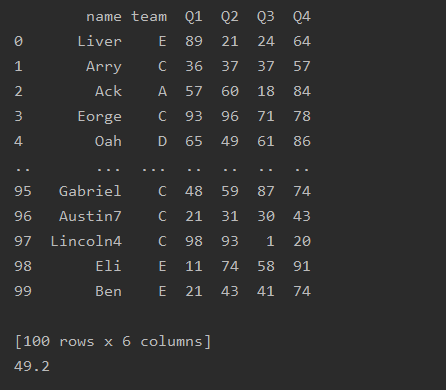
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df)
print(df['Q1'].mean())
指定单行
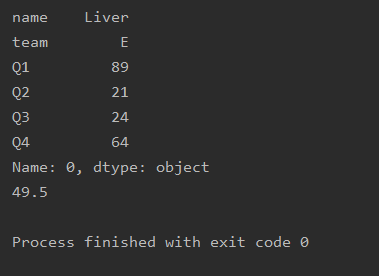
因为前两个数据是str类型 所以要使用切片
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.loc[0])
print(df.loc[0][2:].mean())
df.round(2) # 指定字段指定保留小数位
df.nunique()# 每个列的去重值的数量
s.nunique() # 本列的去重值
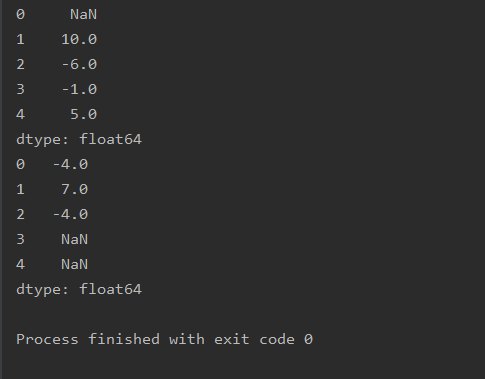
差值
import pandas as pd
df=pd.Series([2,12,6,5,10])
# 当前数与前一个数的差值
print(df.diff())
# 当前数与后面第二个数的差值
print(df.diff(-2))
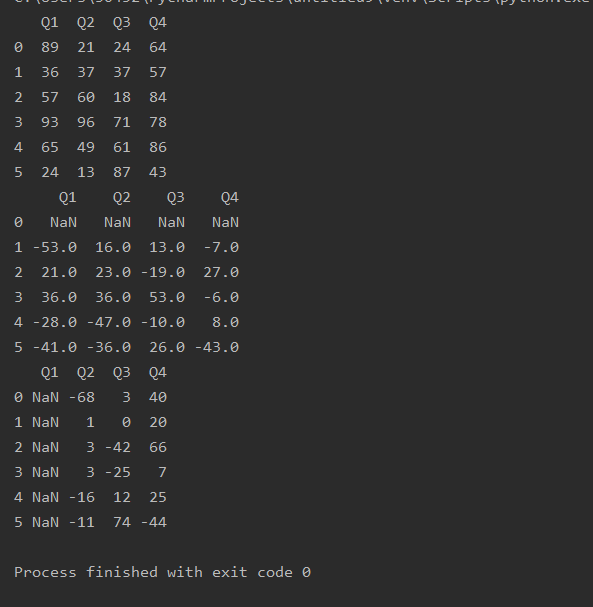
DataFrame
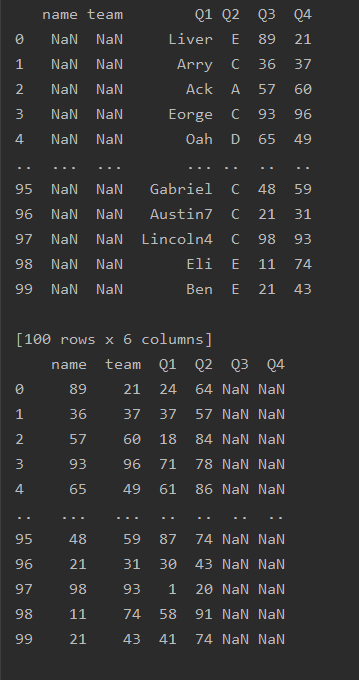
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.loc[:5,'Q1':'Q4'])
print(df.loc[:5,'Q1':'Q4'].diff())
print(df.loc[:5,'Q1':'Q4'].diff(1,axis=1))
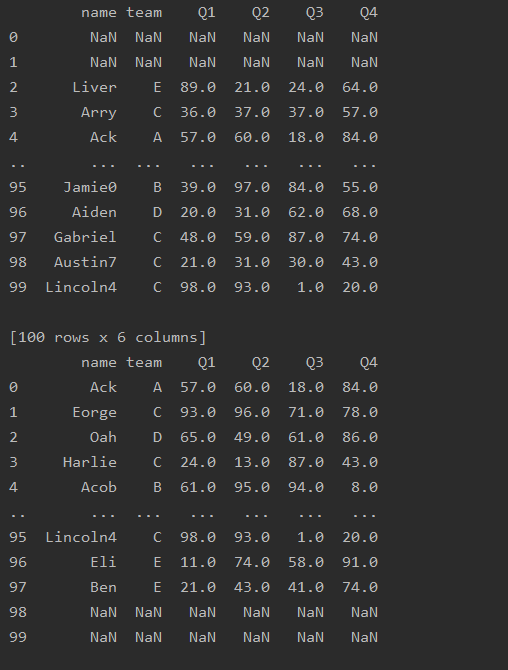
位置移动
import pandas as pd
df=pd.read_excel('text.xlsx')
# 向下移动2行
print(df.shift(2))
# 向上移动2行
print(df.shift(-2))
# 向左移
print(df.shift(2,axis=1))
# 向右移
print(df.shift(-2,axis=1))
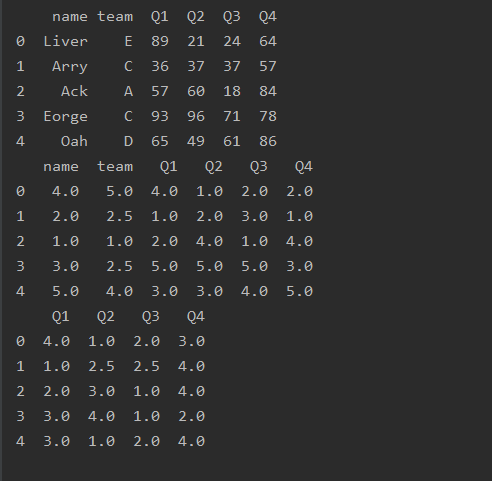
排名rank()
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.head())
print(df.head().rank())
print(df.head().rank(axis=1))
数据选择
| 操作 | 语法 |
|---|---|
| 选择列 | df[x] |
| 按索引选择行 | df.loc[x] |
| 按数字索引选择行 | df.iloc[x] |
| 使用切片选择行 | df[0:x] |
| 用表达式筛选行 | df[x>=0] |
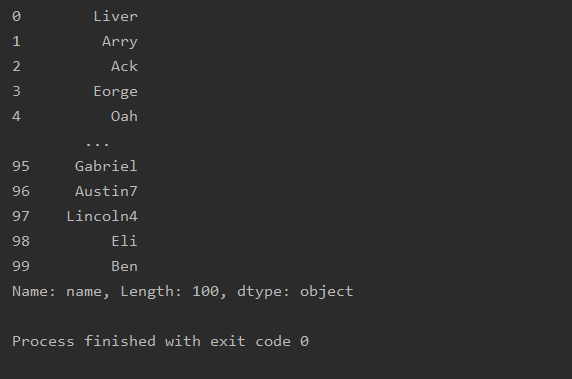
选择列
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df['name'])
切片选择行
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df[:4])
print(df[5:10])
print(df[0::2])
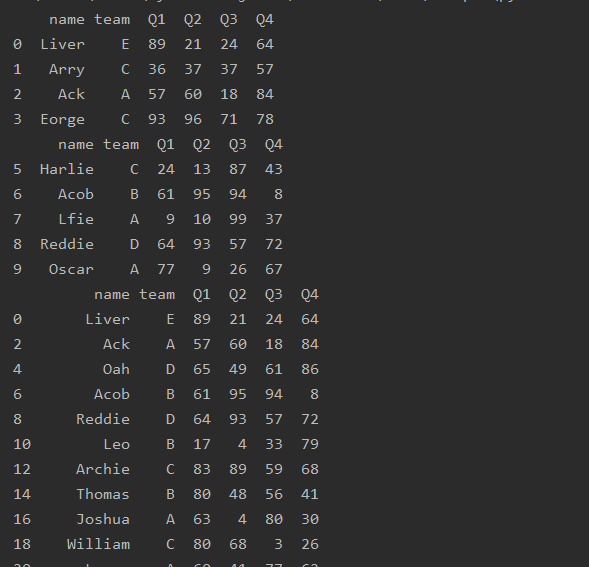
按标签取行 loc
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df.loc['Arry'])
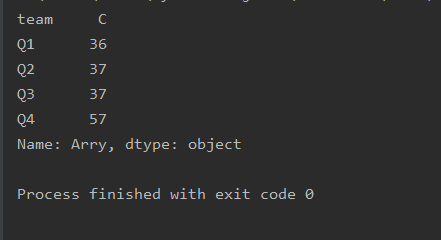
使用切片 选择多个
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df.loc['Arry':'Oah'])
print(df.loc[['Arry','Oah']])
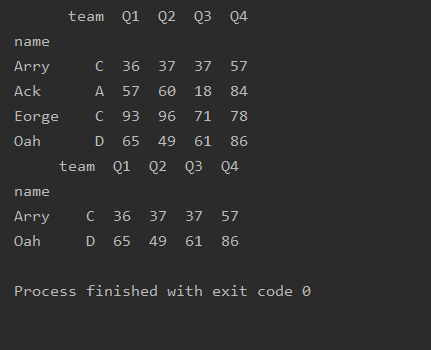
设置读取列
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df.loc['Arry':'Oah',['Q1','Q2']])
按数字索引取行 iloc
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df.iloc[0:3])
print(df.iloc[0:10:2])
# 设置取的列
print(df.iloc[0:5,[0,1]])
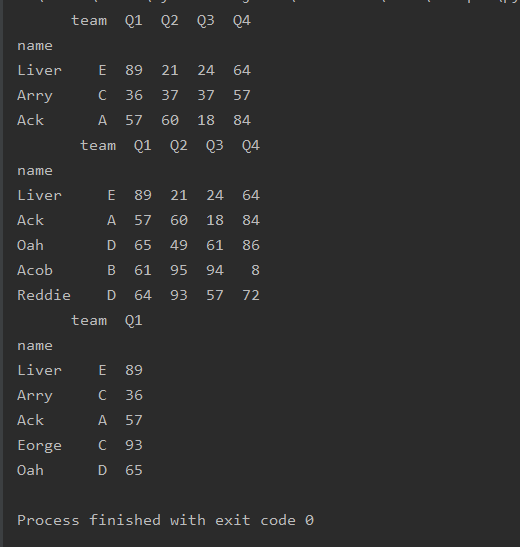
取具体值
at[] iat[] 前一个参数为索引 后一个参数为列名 iat按数字索引获取
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df)
print(df.at['Arry','Q1'])
print(df.iat[1,1])
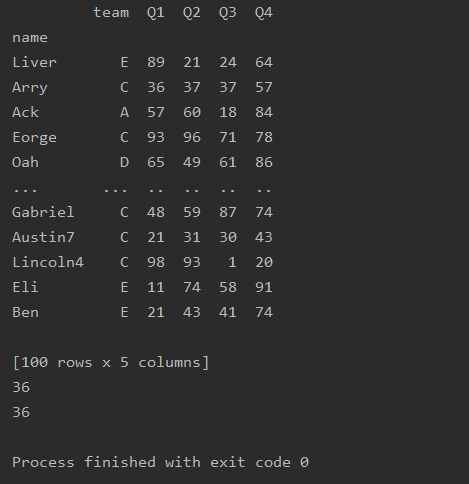
get 获取某列
import pandas as pd
df=pd.read_excel('text.xlsx',index_col='name')
print(df.get('team',0))
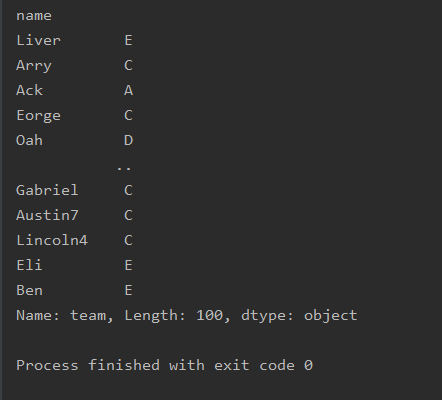
截取数据
注意只能是数字索引
import pandas as pd
df=pd.read_excel('text.xlsx')
print(df.truncate(before=2,after=6))