
2020年6月OpenAI发布了最新的GPT-3模型,它不仅能够实现一些强大的自然语言处理功能,还带来了另外一项有趣的突破–能够生成React代码。
在Python代码中,很多工程相关的代码也是使用各种第三方工具包进行完成。以数据分析为例,会在很多地方用到pandas,但是,往往繁琐的命令和复杂的语法很难记住。然而,在一些博客和网站找到对应的代码片段又需要修改一些变量和列名。
收到GPT-3的启发,开发人员考虑,是否可以把自动生成代码引入到Jupyter Notebook中,开发一款Jupyter Notebook插件,让它能够实现通过自然语言描述轻松转化成代码。
于是,本文的主角–Text2Code就应用而生了,本文就来介绍一下它的使用。
Text2Code
功能:
Text2Code[1]是一款Jupyte Noteboo插件,它能够实现从英文自然语言描述到Python代码的轻松转换。
换句话说,你只需要用英文描述一下你想完成的功能,Text2Code就可以把它转化成Python代码。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以价位@762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
例如,你给出一段英文描述:
group the df by heroes_gender and get min, max, mean and sum of episode_duration
然后,它就会在cell中生成代码片段:
df[['heroes_gender', 'episode_duration']].group_by(['heroes_gender']).agg(['min', 'max', 'mean', 'sum'])
实现
Text2Code建立在可扩展的监督模型基础上进行开发而成,它主要包含如下部分:
- 生成/收集训练数据
- 意图匹配:用户想要做什么?
- 命名实体识别:识别句子中的变量(实体)
- 填充模板:在固定模板中使用提取的实体生成代码
- 封装Jupyter Notebook扩展
使用方法
Jupyter Notebook的安装步骤如下:
$ git clone https://github.com/deepklarity/jupyter-text2code.git$ cd jupyter-text2code$ pip install .
使用详细说明如下:
- 打开Jupyter Notebook
- 如果前面安装成功,那么第一次从 tensorflow_hub 下载 Universal Sentence Encoder 模型
- 点击菜单上出现的Terminal图标(激活扩展)
- 键入 "help "查看当前支持的命令列表
生成训练数据
为了生成训练数据,开发者模拟用户要向系统查询的内容,先用一下自己认为的格式给出一段英文描述。

找出一段英文描述中的关键词,然后用生成器去生成一些关键词,来替代实现数据集中的内容,以此来生成训练数据。
意图匹配

在生成数据后,这些数据被映射为特定意图的唯一 “intent_id”,然后使用Universal Sentence Encoder来获取用户查询的嵌入,并找到与预定义意图查询(生成数据)的余弦相似性。Universal Sentence Encoder类似于word2vec,它可以生成嵌入,但针对的是句子而不是单词。
命名实体识别
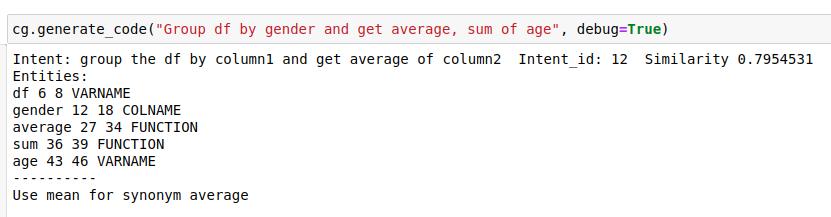
生成的数据可以用来训练一个自定义的实体识别模型,它可以检测列名、变量、库名。为此,开发人员探索了HuggingFace模型,但最终还是使用Spacy来训练自定义模型,主要是因为HuggingFace模型是基于变换器的模型,相对于Spacy来说有点重。最后,如果你的时间不是很紧张,并且又想快速的python提高,最重要的是不怕吃苦,建议你可以价位@762459510 ,那个真的很不错,很多人进步都很快,需要你不怕吃苦哦!大家可以去添加上看一下~
填充模板

只要正确识别实体,正确匹配意图,填写模板就非常容易。例如,"show 5 rows from df "查询会得到两个实体:一个是变量,一个是数字。对此,模板代码的编写很直接。