
HashMap
1.hashMap数据结构:
jdk1.7:数组加链表,jdk1.8之后是数组加链表加红黑树,相比 jdk1.7 的 HashMap 而言,jdk1.8最重要的就是引入了红黑树的设计,当hash表的单一链表长度超过 8 个的时候,链表结构就会转为红黑树结构。
为什么要这样设计呢?好处就是避免在最极端的情况下链表变得很长很长,在查询的时候,效率会非常慢。
HashMap集合了数组和链表的优点实现了利用数据来查询,链表来删除的方式,使他们的查询和删除的操作都很快。
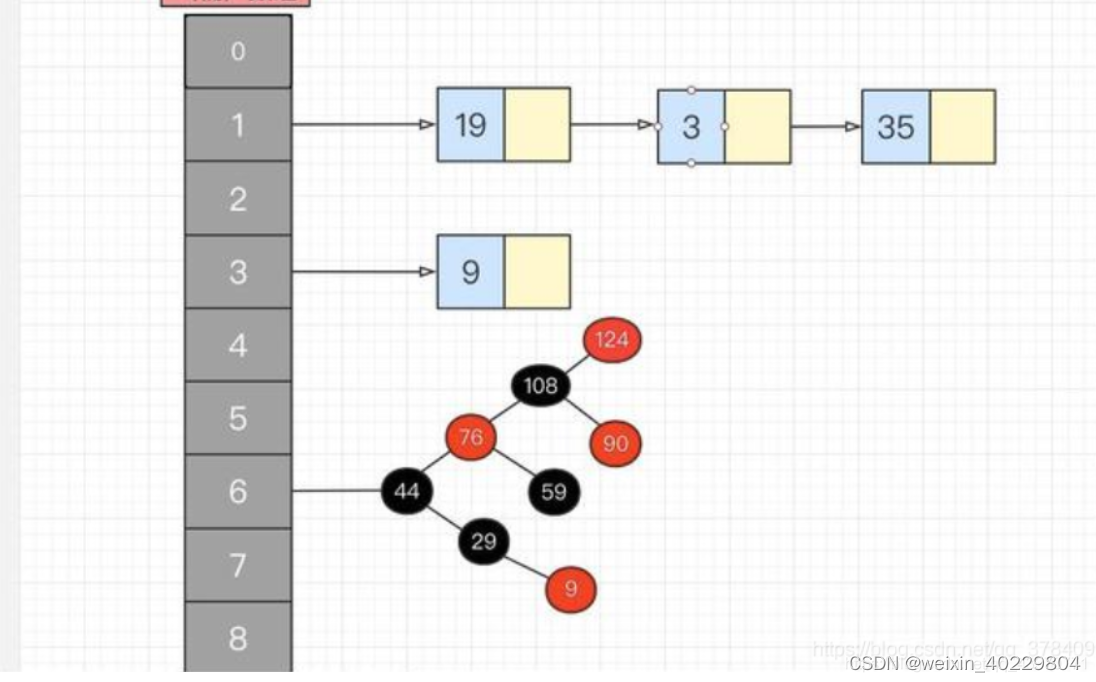
2.jdk1.8还有一个很大的改动就是将头插改成了尾插
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
// 获取entry在原链表(未扩容前)的next
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
int i = indexFor(e.hash, newCapacity);
// 将当前entrydenetx指向新数组对应index的值,即头插法(新来的在最上面)
e.next = newTable[i];
// 将新数组对应位置占据
newTable[i] = e;
// 进入下一个节点的循环
e = next;
}
}
}
此处就会有很大问题:
假设有T1,T2两个线程同时对一个HashMap进行put操作,刚好,HashMap达到了扩容的条件,
这是两个线程都会去对这个HashMap进行扩容。
链表A–>B,假设A B扩容后,计算的index依然相同,那么他们还会存放在同一链表中
假设当T1线程进入到transfer时,先会拿到A,Entry<K,V> next = e.next拿到B,这时T1线程被挂起。
T2线程进入transfer时,先会拿到A,Entry<K,V> next = e.next拿到B,然后向下执行,将A放入index,
之后循环至B,B继续执行时,就会将B.next->A, 特别注意,新数组属于线程专属的,但AB这种Enrty是
从原数组拿到的,所以它们属于全局的,T2修改了B的next,将其指向A.
T2线程执行完之后,T1继续执行,将A放入index,循环至B, 此时B的next指向A(T2做了全局的修改),
B执行完后。循环发现B.next!=null,将其取出继续循环,即A又执行了一次,根据头插法,A的next又指向B.
当使用get获取元素时,发现A.next=B,B.next=A;形成环状,导致查询出现了死循环。
而尾插法是直接在尾部插入不会对之前的链表做修改
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;
int newCap, newThr = 0;
if (oldCap > 0) {
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
newCap = oldThr;
else { // zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
Node<K,V> e;
if ((e = oldTab[j]) != null) {
oldTab[j] = null;
if (e.next == null)
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof TreeNode)
((TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
Node<K,V> loHead = null, loTail = null;
Node<K,V> hiHead = null, hiTail = null;
Node<K,V> next;
do {
// 尾插法,直接在末尾插入对应元素,不会变化原Node的next关系,所以不会出现死循环
next = e.next;
if ((e.hash & oldCap) == 0) {
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
hiTail.next = null;
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}
3.1.8之后hashmap扩容不需要rehash
通过扰动函数(扰动函数是hash函数拿到k的hashcode值,这个值是一个32位的int,让高16位与低16位进行异或)和index值就可以确定扩容之后对应的位置