
分布式唯一id的生成?
利用数据库自增ID
优点:最简单。 缺点:单点风险、单机性能瓶颈。
Twitter Snowflake
优点:高性能高可用、易拓展。 缺点:需要独立的集群以及ZK。
美团做法
时间戳+用户标识码+随机数
优点:
方便、成本低。
基本无重复的可能。
自带分库规则,这里的用户标识码即为用户ID的后四位,在查询的场景下,只需要订单号就可以匹配到相应的库表而无需用户ID,只取四位是希望订单号尽可能的短一些,并且评估下来四位已经足够。
可排序,因为时间戳在最前面。
缺点:
长度稍长,性能要比int/bigint的稍差等
如果非要自增的,可以用redis。如果要的比较频繁可以一次多给这次请求一些。
var什么意思 char varchar区别
var是变量的意思 char是定长 varchar是变长的,有长度信息
索引 需求量很强烈,但增加后影响了插入效率,怎么取舍,不取舍怎么实现
建立索引之后,是增加查询的效率,相应的插入的效率就会降低
如果插入影像到了用户体验,可以考虑去掉索引或者分表
数据库乐观锁的使用场景以及原理
读多写少,增加version字段,每次去比较一下
数据库悲观锁的使用场景以及原理
写多读少,数据库行锁
为什么内存索引用红黑树,数据库索引用B+树
一个读内存,一个是读文件,相比较读文件内存的速度可以说是急速无比,那么树的高度就可以忽略。相反的文件的一次io时间很长,我们尽量将树的高度降低并让读进来的每一页有用的信息尽可能多。
为什么联合索引有最左前缀原则
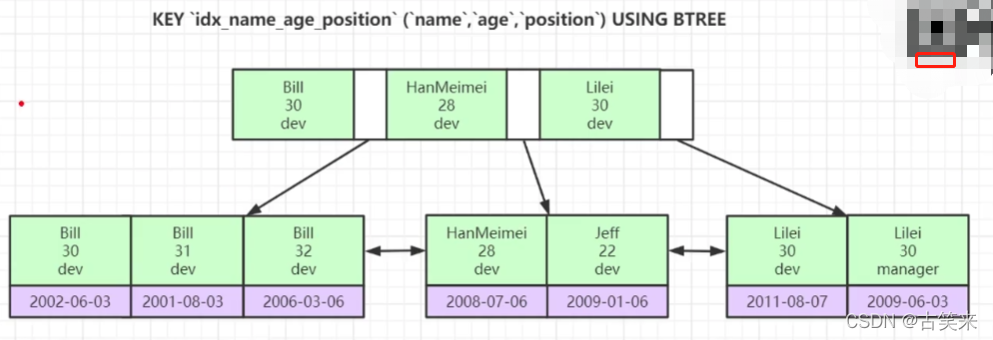
联合索引底层也是B+Tree
当你跳过前面的一个元素,后边元素就不是有序的了,根据叶子节点的指针范围查找就会出错
数据库三范式
https://segmentfault.com/a/1190000013695030
原子性:表字段不可再分。例如年月日,还认为可以被分为年、月、日则不满足
唯一性:表字段不存在部分依赖 。一个字段依赖另一个字段
冗余性:表字段不存在传递性 。学号 学生 学院 学院电话
一般满足这第三范式就可以了。数据库设计的时候可以使用三范式,在真正开发的过程中冗余,减少连表,以空间换时间
数据库怎么解决高并发的读
主从架构,主写,从读。从节点的数量可以根据数据量的大小而定
怎么解决高并发的写
大到一个数据库扛不住的时候,可以分表,把相同的结构的表分到不同的数据库中
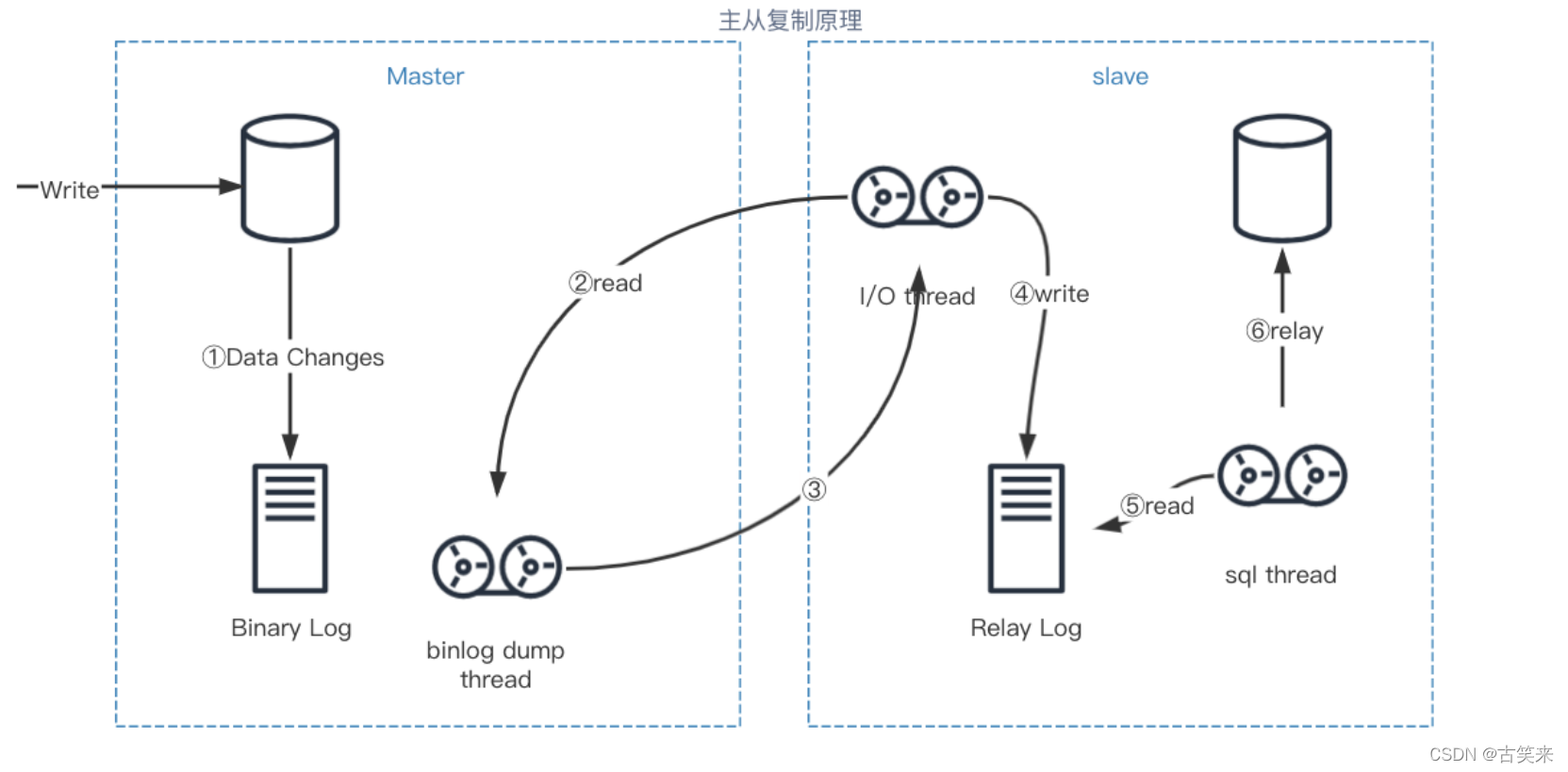
mysql集群中主从数据不一致问题怎么解决
对于一个应用中只有极少的需求要读写完全一致的话,可以让这样的请求读主库
如果从节点也非要一致的话,可以等从节点都写完,再ack。
为什么要将子查询 优化成 联合查询
https://blog.csdn.net/qq_36910634/article/details/106192100
子查询有建临时表和销毁临时表的过程
联合查询是嵌套查询,小表驱动大表,数据量小的时候还可以
遇到过那些数据库问题?怎么发现?
接口返回时间达到秒级,debugger可以发现,数据库查询占用的大部分时间。
怎么解决的?
我们接口接口大于一秒就要说明原因,平时的数据库优化主要有这几个方面
是否返回必要的字段
子查询变join,小表驱动大表
索引是否生效
是否会回表
优化过那些索引?那个索引比较了解
之前有一个千万级的表,做名称模糊查询,要求是前后两边模糊,深入研究过 pg-gin.note 。他是一个倒排索引
一条sql输出状元?
select name,sum(score) s_score from “user” group by name order by s_score desc
一条sql输出每一科的状元
select ta.name,tb.b_course,tb.b_score from “user” ta left join (SELECT max(score) as b_score,course as b_course FROM “user” GROUP BY course) tb on ta.score=tb.b_score and ta.course=tb.b_course where tb.b_score is not null