
集合概念
● 当我们需要保存一组一样(类型相同)的元素的时候,我们应该使用一个容器 来存储,数组就是这样一个容器
数组就是容器:同一类型 创建时指定容量 长度不变 在内存空间中连续存储的
不足:长度固定不能改变
● 然而在我们的开发实践中,经常需要保存一些变长的数据集合,于是,我们需 要一些能够动态增长长度的容器来保存我们的数据。
需求:程序在运行中 数据数量随时会发生变化。
需求的存储结构也会有特殊的需求(增删多 链表结构 查询多 数组结构)
而我们需要对数据的保存的逻辑可能各种各样,于是就有了各种各样的数据结 构。Java中对于各种数据结构的实现,就是我们用到的集合
集合体系
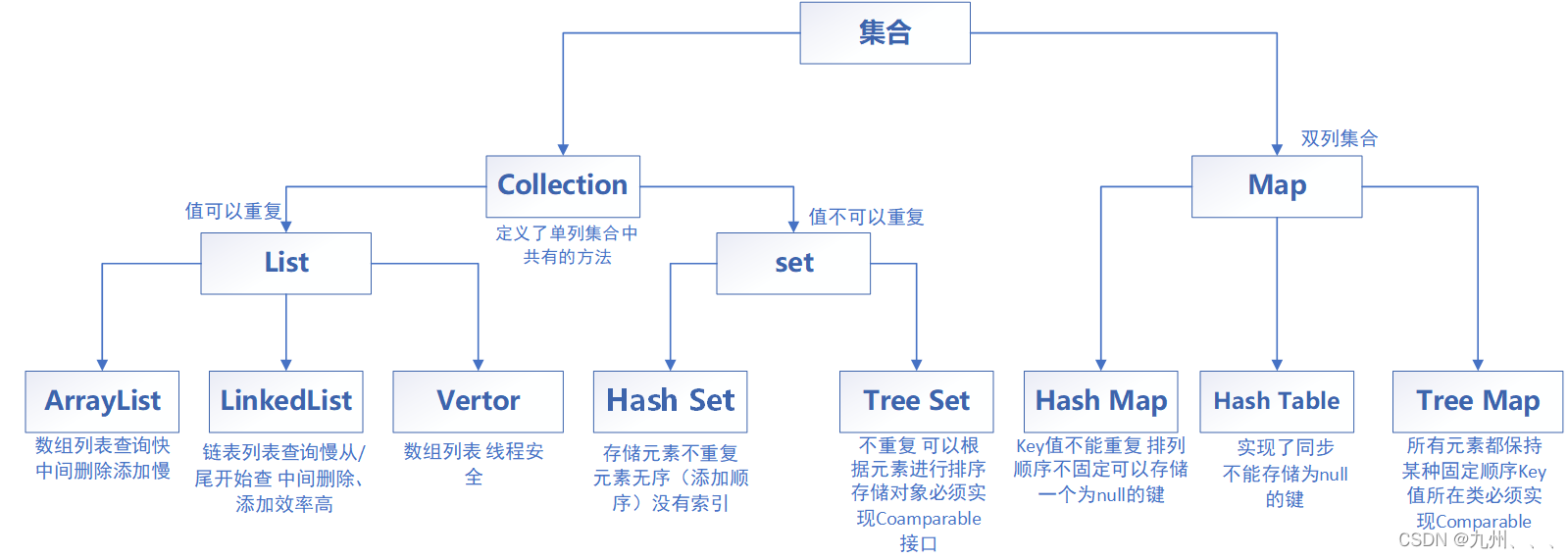
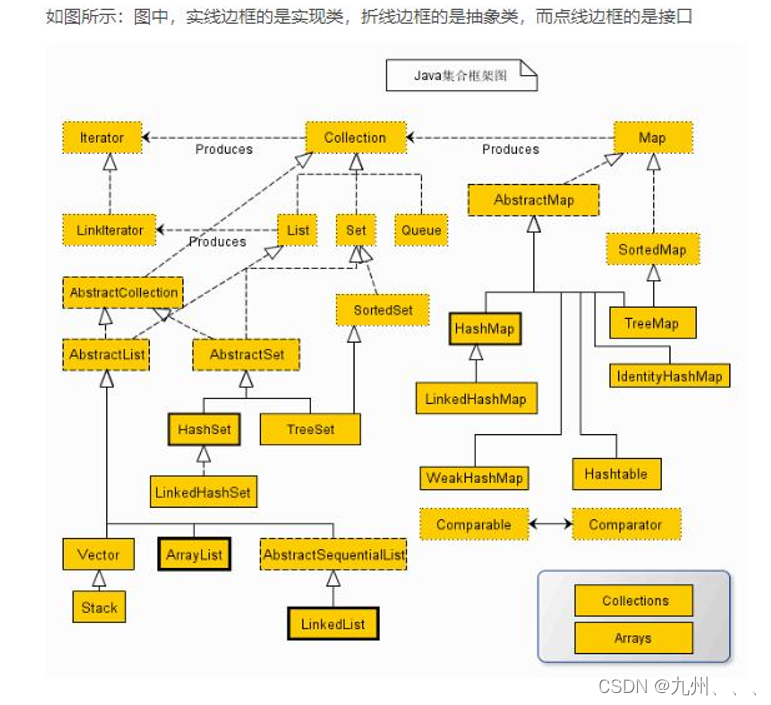
集合体系概述 Java的集合框架是由很多接口、抽象类、具体类组成的,都位于java.util包中。、
Collection接口
Cillection接口中常用的方法
JAVA中集合类默认使用泛型,如果没有定义集合中存储的数据类型,默认数据类型为Object
建议使用泛型语法为集合指明数据类型,类型统一就不会出现转型问题。
● Collection 接口-定义了存取一组对象的方法,其子接口Set和List分别定义 了存储方式。 ● Set 中的数据对象没有顺序且不可以重复。 ● List 中的数据对象有顺序且可以重复。 在Collection 中定义了一些集合中的共有方法: add(Object element); 添加元素 addAll(Collection c); 把一个集合添加到这个集合中去
remove(Object element); 删除指定元素 removeAll(Collection c);删除指定集合 不包含时,删除相交的元素 void clear(); 删除集合中所有的元素 int size(); 集合长度 boolean isEmpty(); 判断集合是否为空 boolean contains(Object element); 判断是否包含指定元素 boolean containsAll(Collection c); 判断集合中是否包含这个集合 boolean retainAll(Collection c);求交集,集合数据发生变化返回true,不变返回false。
List接口以及实现类
ArrayList
Array List 数组列表 实现长度可变的数组,在内存中分配连续空间 数据采用数组方法储存(查询快 中间开始 添加、删除效率低)
Linked List 链表 查询慢 从头或者尾结点开始查询 中间删除、添加效率高
Vector 数组列表 线程安全
ArrayList<String> alist=new ArrayList<String>();
创建对象时不会创建数组,第一次添加时创建容量为10的数组
添加元素:先判断元素添加进去后,数组是否能放下,如果可以,直接添加,如果不可以会创建一个新的数组(扩容)
alist.add("f");//添加元素
alist.add(2,"f");//给指定位置添加元素, 指定的索引不能大于size
alist.clear();//删除所有元素
System.ouot.println(alist.get(2));//返回数组第二个元素
alist.remove(2);//删除特定元素
alist.set(2,"H");//替换第二元素位置为H
alist.size();//数组长度
System.out.println(alist.indexof("a"));//返回在数组中可以找到指定元素的第一个索引,找不到返回-1
LinkedList
元素可以重复 按照添加顺序排放 链表
LinkedList<String> list =new LinkedList<String>();
Vector 可扩展的对象数组
Vector<String> v=new Vector();
底层数组实现 是线程安全
List接口集合迭代
for循环:支持在遍历过程中删除集合中的元素,注意索引变化
增强for循环:不支持在遍历时删除元素,如果删除 抛出java.until.Exeception
删除元素会报错,break结束循环,可以继续向后循环。
for(String c:alist){ }
alist 数组或集合名
迭代器(Iterator)
Iterator<String> it=alist.iterator();
while(it.hasNext()){
String item=it.next();
if(item.equals("a")){
it.remove();//删除当前指针指向元素
}
}
Iterator<String> its=alist.iterator(alsit.size);
while(its.hasPrevious()){
String item=its.previous();
}//ListIterator(集合长度)逆序输出集合中的元素 只能遍历List接口下的集合
set
接口有两个实现类
储存 元素不重复 没有索引 元素无序(添加顺序)
set接口继承了Collection接口/List添加顺序排放
HashSet
HashSet<String> c=new HashSet<>(); c.add();//添加元素
Set元素只能用于增强for循环和迭代遍历
TreeSet
不重复 可以根据元素进行排序
储存对象必须实现Comparable接口
Map
Map: 双列储存 键---值 键不允许重复 值可以重复
实现类:
Hash Map
Tree Map
Hash Table
Hash Map:
Map<String,String>map=new HashMap<String,String>();
map.put("a","aa");//添加键和值
map.remover("a")//通过指定的键 返回对应的值(值也被删掉)
map.get("a");//根据2键找到对应值
map.size();//有几组键值对
map.keyset();//只输出键的一列
可以储存一个为Null的键
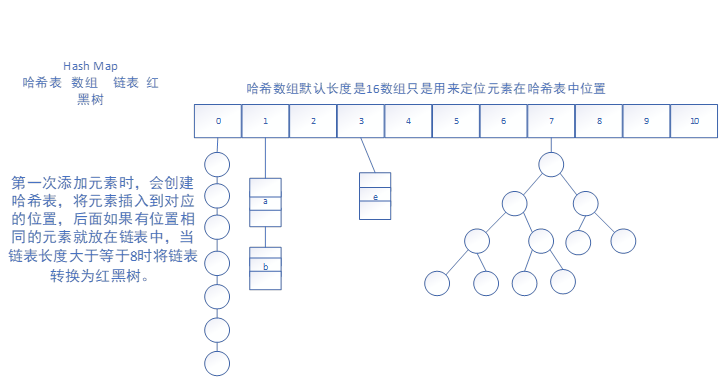
哈希函数可以根据内容的哈希表计算
第一次添加元素时,会创建哈希表,将元素插入到对应的位置,后面如果有位置相同的元素就放在链表中,当链表长度大于等于8时将链表转换为红黑树。
Hash Table
不允许为Null的键(key)
Hash Table:
Hashtable<String,String> map=new Hashtable<>();
map.put("a","aaa");//添加键和值
key.HashCode();
是线程安全,锁住了整个put(),访问较小时可以使用,访问很高时,效率太低了,后面会有新的安全线程类代替。
Tree Map
根据键的自然顺序来进行排列。
map遍历方式1
Set<String>Ketset=map.Key();
for(String Key :Keyset){
System.out.println(Key);
}
map遍历方式2
Set<Entry<String,String>>entryset=map.entrySet();
for(Entry entry : entrySet){
System.out.println(entry.get()+": :"entry.getValue());
}
把map中的键值对封装在一个Entry对象中,将多个Entry对象装进Set集合中。(Entry对象包含键值)
Collection类
是集合的工具类与数组工具Arrays类似
public static void test2(int b,int...a){ }//b=1,a=2,3,4,5
public static void test1(){test2(1,2,3,4,5)}
int...a定义可变长度参数,本质是数组,一个参数列表中只能有一个,并且放在参数列表的最后一位。
List<Integer> list=new ArrayList<>(); Collections.addAll(list,1,2,3,4,5); Collections.Sort();//排序 Collections.binarySearch(list,4);//查找元素位置 Collections.Swap(list,0,3)//元素位置交换 Collections.copy(list,list1);//将list1中元素复制到list中去 listsize>list1size (不是添加) List<Integer>list2=Collections.emptyList();//返回一个空集合 避免在判断时出现空指针 集合不能用 Collections.max(list);//返回最大值 Collections.min(list);//返回最小值 Collections.replaceAll(list,2,6);//将元素中2替换为6 Collections.reverse(list);//对集合进项逆序操作
泛型
早期的Object类型可以接收任意的对象类型,但是在实际的使用中,会有类型转换的问题。也就存在这隐患,所以Java提供了泛型来解决这个安全问题.
泛型的主要作用是在编译期间对类型进行明确。
● 泛型,即“参数化类型”。一提到参数,最熟悉的就是定义方法时有形参,然后调用此方法时传递实参。 ● 参数化类型,就是将类型由原来的具体的类型参数化,类似于方法中的变量参数,此时类型也定义成参数形式,然后在使用/调用时传入具体的类型
参数化类型 把类型作为参数传进去
JAVA中希望集合存储同一类型,使用泛型语法,在创建对象时,把类型当做参数传递出去 ,这样集合中的类型就明确了。
参数的类型参数只能是类类型 泛型的参数类型可以是多个 如果未定义创建对象 类型为Object
从泛型类派生子类
泛型类接口
子类和父类都是泛型类
创建子类对象时传入类型,父类与子类的类型一致
如果子类不是泛型类,那么明确父类类型
因为子类如果不是泛型类 创建子类类型时 不能传入类型,父类类型也就无法明确。
子类也是泛型类,子类和父类的泛型类型要一致
class A<T> extends Demo<T>
子类不是泛型类,父类要明确泛型的数据类型
class A extends Demo<String>
泛型通配符
类型通配符一般是使用"?"代替具体的类型实参。
所以,类型通配符是类型实参,而不是类型形参。
Demo B<? supr Number>
类型下限Number
只能传入Number类型以及Number父类
Demo <? extends Number>
类型上限Number
要求该泛型的类型,只能是实参类型,或实参类型的子类类型。
类型擦除
泛型是Java 1.5版本才引进的概念,在这之前是没有泛型的,但是,泛型代码能够很好地和之前版本的代码兼容。那是因为,泛到信息只存在于代码编译阶段,在进入JVM之前,与泛型相关的信息会被擦除掉,我们称之为一类型擦除。 泛型信息只存在于代码编译阶段,在进入 JVM 之前,与泛型相关的信息会被擦除掉,专业术语叫做类型擦除。