
前 言 : \textcolor{green}{前言:} 前言:
❤️目前正在学习周志华的机器学习,我是根据B站的视频来学习,讲的比较扣书本上的知识点。但是建议还是需要看书,书本上的内容是比较全的,但是也比较难,配合着来学习是个比较不错的选择。
❤️本章的学习是非常枯燥的,但也是基础,它的目的我在文章中也有提到,是使学得的模型能很好得使用于“新样本”。有人在这里就打了退堂鼓,建议先看后面来学,但是我的话希望能先把这里 啃 \textcolor{red}{啃} 啃下来,后面的内容就是用到什么学什么。
💢这本书上的知识那必须整起来,刚开始接触这个,确实让我有点脑袋发热,更何况让我去讲了。真正站上去的时候,尤其是回答问题,脑袋瓜子那简直是嗡嗡嗡。😤
💞同时希望我们可以一起学习,一个人的学习那必然是枯燥无味的,一起抱团才是王道~~~💞
机器学习之模型评估与选择
- 二、模型评估与选择
- 2.1 经验误差与过拟合
- 2.2 评估方法
- 2.2.1 留出法(hold-out)
- 2.2.2 交叉验证法
- 2.2.3 自助法
- 2.2.4 验证集(调参与最终模型)
- 2.2.5 总结
- 2.3 性能度量
- 2.3.1 错误率与精度
- 2.3.2 查准率与查全率
- 2.3.3 ROC与AUC
- ROC曲线
- AUC
- 2.3.4 代价敏感错误率与代价曲线
- 2.4 比较检验
- 2.4.1 假设检验
- 2.5 偏差与方差
机器学习的目标是使学得的模型能很好得使用于“新样本”。
二、模型评估与选择
目的:主要是要一种让自己做模型的一种思想。否则自己的思想会跟着所写之人的思想走。
2.1 经验误差与过拟合
m \textcolor{red}{m} m个样本数量, Y \textcolor{red}{Y} Y表示样本正确的结果,通过使用模型进行预测判断,得到结果 Y ′ \textcolor{red}{Y'} Y′。其中有 a \textcolor{red}{a} a个错误
则“错误率”(error rate):E = a / m
"精度"(accuracy):1 - E (精度通常写成%)
“误差”(error):|Y - Y'|
学习器在训练集上的误差称为“训练误差”(training error)或“经验误差”(empirical error);
在新样本上的误差称为“泛化误差”(generalizationerror);
关于
过拟合(overfitting)和欠拟合(underfitting)
最希望的是从训练样本中进可能的学出适用于所有潜在样本的“普遍规律”,以达到拿到新的样本可以做出正确的判别。
当学习能力太强,导致把样本本身的特性(不太一般的特性)成为了一般性质,这就导致了泛化性能下降,这就是Overfitting,反之,连一般的特性都没学习到,这就成为了Underfitting。要知道Overfitting是无法彻底避免的,只能缓解;而Underfitting是比较容易克服的。
2.2 评估方法
泛化能力:模型对没有见过的数据的预测能力;(训练集和测试集)
训练集(trainning set)
测试集的保留方法(testing set):留出法;交叉验证法;自助法
验证集(validation set)
2.2.1 留出法(hold-out)
holid-out:直接将数据集D划分为两个互斥的集合,其中一个集合作为训练集S,另一个作为测试集T。即 D = S ∪ T, S ∩ T = Φ 。
三七分
比如D含有1000个样本,划分S有700,T有300。若T有90个错误,那错误率(90/300)*100%=30%,精度为70%。
分层采样(stratified sampling)
比如D含有1000个样本,其中包含500个正例,500个反例。通过分层采样获得70%训练集,30%测试集,那么在S中应该包含350个正例+350个反例。T中150+150。
注意:
- 不同的划分会导致不同的训练/测试集,模型评估结果会有差别;
- 单词留出法得到的结果不稳定可靠,一般会多次随机划分、重复实验取平均值。
窘境
训练集大,测试集小–>模型更加接近于D训练出的模型–>评估结果不稳定准确(方差较大)
训练集小,测试集大–>S与D训练出的模型差别更大–>降低了评估结果的保真性(fidelity)(偏差较大)
2.2.2 交叉验证法
交叉验证法(cross validation)先将数据集D划分为k个大小相似的互斥子集 D = D 1 ∪ D 2 ∪ . . . ∪ D k D = D_1 ∪ D_2 ∪...∪D_k D=D1∪D2∪...∪Dk, D i ∩ D j = Φ D_i ∩ D_j = Φ Di∩Dj=Φ。每个子集 D i D_i Di都尽可能保持数据分布的一致性,即从D中分层采样得到。每次用k - 1个子集的并集作为训练集,剩下的一个子集作为测试集,得到k组训练/测试集,进行k次训练和测试,最终返回k个测试结果的均值。又称为”k折交叉验证法“(k-fold cross validation)。
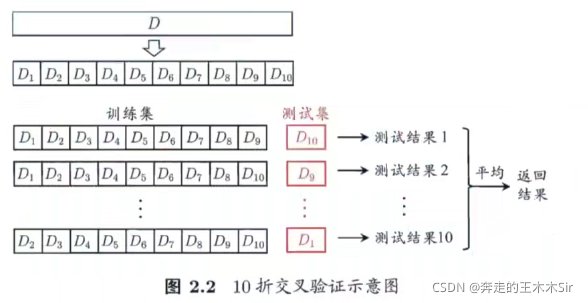
注意:10次10折交叉验证与100次留出法都是进行了100次训练/测试
留一法(Leave-One-Out,简称LOO)
若数据集D中有m个样本,令k = m时,就得到了一种特例,m种样本划分m个子集(每个子集种含有一个样本);
留一法的评估结果被认为时比较准确的是因为,留一法使用的训练集与初始数据集相比只少了一个样本,这就使得被实际评估的模型与期望评估的用D训练出的模型很相似。
缺点
数据量较大时,计算开销时非常大的。
2.2.3 自助法
“自助法”(bootstrapping)是一个比较好的解决方案,它直接以自助采样法(bootstrap sampling)为基础 [Efron and Tibshirani,1993]。给定包含m个样本的数据集D,我们对它进行采样产生数据集D’:每次随机从D中挑选一个样本,将其拷贝放入D’,然后再将该样本放回初始数据集D中,使得该样本在下次采样时仍有可能被采到;这个过程重复执行m次后,我们就得到了包含m个样本的数据集D’,这就是自助采样的结果。显然,D中有一部分样本会在D’中多次出现,而另一部分样本不出现。可以做一个简单的估计,样本在m次采样中始终不被采到的概率是 ( 1 − 1 m ) m (1 - \frac{1}{m}) ^ m (1−m1)m,取极限得到
lim m → + ∞ ( 1 − 1 m ) m − > 1 e ≈ 0.368 \lim_{m\rightarrow+\infty}(1 - \frac{1}{m})^ m -> \frac{1}{e} ≈0.368 m→+∞lim(1−m1)m−>e1≈0.368
就是说通过自助采样,初始数据集D种约有36.8%的样本未出现在采样数据集D’中。最终将D’用作训练集,D\D’为测试集。这样的测试结果叫**”包外测试“**(out-of-bag estimate)
优势与缺点
优点:数据集较小、难以有效划分训练/测试集时很有效;能从初始数据集中产生多个不同的训练集,有利于集成学习(第八章)等方法。
缺点:改变了初始数据集的分布,引入估计偏差。
估计误差,是指数据处理过程中对误差的估计,有多种统计表示方式。在统计学中,估计误差是此估计量的期望值与估计参数的真值之差。误差为零的估计量或决策规则称为无偏的。否则该估计量是有偏的。在统计中,“误差”是一个函数的客观陈述。
Example:
比如一组数字{1,2,3,4,5,6,7,8,9,10}。我们从中选择一个数字总共10个位一组采样{2,6,3,5,…},在这组数字中有那么几个数字是没有,那么就把他定为测试集,余下的为训练集。
2.2.4 验证集(调参与最终模型)
大多数的学习算法都有参数(parameter)需要设定,参数配置不同,学得模型的性能上有显著差别,因此在进行模型评估与选择时,要对适用学习算法进行选择,还需要虽参数进行设定。这就是”参数调节“或”调参“(parameter tuning)
Example:
三个参数,每个参数5个候选值。对于一个训练/测试集就有 5 3 = 125 5^3 = 125 53=125个模型要考察。
注意:通常把学得模型在实际使用中遇到的数据称为测试数据,为了加以区分,模型评估与选择中用于评估测试的数据集称为”验证集“(validation set)
整体的一个过程:
现在训练集上训练–>验证集上去验–>得到结果–>去调参–>再去训练集上训–>…–>得到的结果是ok了–>最终去测试集上测
这里是一个重点,调参我们要去调到适合我们的模型的参数,需要大量的实验要进行找到最适合的。不可能说你做了一次就说这个最好,你说信我都不会信,这需要去证明。
2.2.5 总结
要知道在什么时候去用什么方法。
2.3 性能度量
性能度量(performance measure)衡量模型泛化能力的评价标准。
**描述:**在预测任务中,给定样例集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x i , y i ) D = {(x_1,y_1),(x_2,y_2),...,(x_i,y_i)} D=(x1,y1),(x2,y2),...,(xi,yi)。其中 y i y_i yi是示例 x i x_i xi的真实标记,要评估学习器f的性能,就要把学习器预测结果 f ( x ) f(x) f(x)与真实标记 y i y_i yi进行比较。
均方误差(mean squared error)
回归任务最常用的性能度量是“均方误差”
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
(
f
(
x
i
)
−
y
i
)
2
E(f;D) = \frac{1}{m}\sum_{i=1}^{m}(f(x_i) - y_i)^2
E(f;D)=m1i=1∑m(f(xi)−yi)2
更一般的,对于数据分布
D
D
D和概率密度函数
p
(
•
)
p(•)
p(•),均方误差可描述为
E
(
f
;
D
)
=
∫
x
~
D
x
(
f
(
x
i
)
−
y
i
)
2
p
(
x
)
d
(
x
)
E(f;D) = \int_{x~D}{x}(f(x_i) - y_i)^2p(x)d(x)
E(f;D)=∫x~Dx(f(xi)−yi)2p(x)d(x)

2.3.1 错误率与精度
是分类任务中最常用的两种性能度量,既适用于二分类任务,也适用于多分类任务
error rate是分类错误的样本数占样本总数的比例
E
(
f
;
D
)
=
1
m
∑
i
=
1
m
Ⅱ
(
f
(
x
i
)
≠
y
i
)
E(f;D) = \frac{1}{m}\sum_{i=1}^{m}Ⅱ(f(x_i) ≠ y_i)
E(f;D)=m1i=1∑mⅡ(f(xi)=yi)
accuracy是分类正确的样本数占样本总数的比例
a
c
c
(
f
;
D
)
=
1
m
∑
i
=
1
m
Ⅱ
(
f
(
x
i
)
=
y
i
)
=
1
−
E
(
f
;
D
)
acc(f;D) = \frac{1}{m}\sum_{i=1}^{m}Ⅱ(f(x_i) = y_i) = 1 - E(f;D)
acc(f;D)=m1i=1∑mⅡ(f(xi)=yi)=1−E(f;D)
更一般的,对于数据分布
D
D
D和概率密度函数
p
(
•
)
p(•)
p(•),error rate和accuracy可描述为
E
(
f
;
D
)
=
∫
x
~
D
Ⅱ
(
f
(
x
)
≠
y
)
p
(
x
)
d
x
E(f;D) = \int_{x~D}Ⅱ(f(x) ≠ y)p(x)dx
E(f;D)=∫x~DⅡ(f(x)=y)p(x)dx
E ( f ; D ) = ∫ x ~ D Ⅱ ( f ( x ) = y ) p ( x ) d x = 1 − E ( f ; D ) E(f;D) = \int_{x~D}Ⅱ(f(x) = y)p(x)dx = 1 - E(f;D) E(f;D)=∫x~DⅡ(f(x)=y)p(x)dx=1−E(f;D)
比较方式:精度越高,性能越好;错误率越低,性能越好。
2.3.2 查准率与查全率
查准率(precision)与查全率(recall),真正例(true positive),假正例(false position),真反例(true negative),假反例(false negative)
以二分类为例:
预测情况和实际情况的所有情况两两混合,组成混淆矩阵。下图为“混淆矩阵”(confusion matrix)
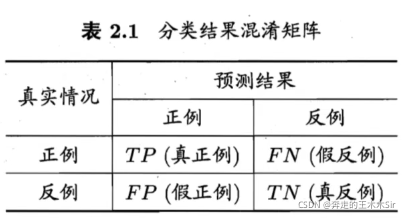
precision:是针对预测结果而言的,是在所有被预测为正的样本中实际为正的样本的概率。(预测的里面有多少个是对的) P = T P T P + F P P = \frac{TP}{TP + FP} P=TP+FPTP
reacll: 是针对原样本而言的,是在实际为正的样本中被预测为正样本的概率。 R = T P T P + F N R = \frac{TP}{TP + FN} R=TP+FNTP
查准率和查全率是一对矛盾的度量,查准率高时,查重率往往偏低;而查全率高时,查准率往往偏低
这 里 有 个 特 别 有 意 思 的 事 情 : \textcolor{red}{这里有个特别有意思的事情:} 这里有个特别有意思的事情:
我在组会上汇报的时候,老师让我用实际例子解释一下这个 P P P和 R R R,它们在什么地方使用;你先回答一下,身份确认和身份识别它的意思是什么?
用很通俗的话来说:身份确认是确认你是你,身份识别是识别出你是谁。怎么样,很通俗吧。反正我当时一愣是没听懂。
再举几个例子:疑罪从无,宁可错杀一千也不让过一个。这个例子中查准率和查全率是?
还有一个是关于病人的,查准率是什么?根据公式我们可以知道它是有多少查出来有病的,它确实有病。那查全率是什么,它是有多少有病的被查出来。
怎
么
样
?
懂
这
个
意
思
了
吗
?
\textcolor{blue}{怎么样?懂这个意思了吗?}
怎么样?懂这个意思了吗?
别问我,我当时在上面愣是站了好长时间,脑袋瓜子嗡嗡的。(现在是懂了)
关于这两个它到底选择哪个为好,这就要根据实际情况来进行了。有时候并不是找它的BEP(平衡点),有时是为了查准率高一下,相应的查全率就会低。所以在做实验的过程中要去找哪个更适合。
P-R图
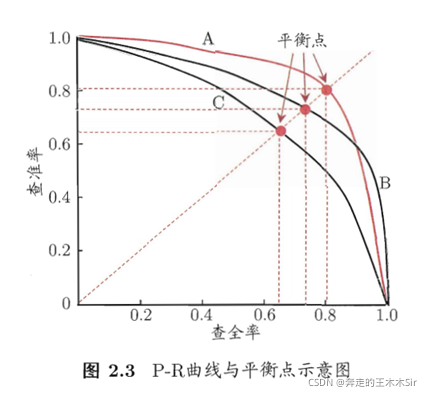
以查准率为纵轴,查全率为横轴,绘制P-R曲线。可以直观的显示学习器在样本总体上的查全率、查准率。
在进行比较时,若一个学习器的P-R曲线被别一个学习器的曲线完全”包住”,则可断言后者的性能优于前者。
- 首先可以确定B和A优于C,BA之间由于交叉无法确定
- 对于BA,可以采用下面的三种方法进行比较
- No.1:比较AB面积的大小,在一定程度上表明了模型的优劣,但是不容易估算
- No.1: F 1 F1 F1
- No.3: F β F_\beta Fβ
最优阈值的确定:BEP,F1度量, F β F_β Fβ
BEP(Break-Even Point):即”平衡点”,它是“查准率=查全率”时的取值。BEP越大,性能越好。
**F1度量:**基于查准率和查全率的调和平均(harmonic mean)。值越大性能越好
F
1
=
2
×
P
×
R
P
+
R
=
2
×
T
P
样
例
总
数
+
T
P
−
T
N
=
1
1
2
(
1
P
+
1
R
)
=
2
T
P
T
P
+
F
P
+
T
P
+
F
N
F1 = \frac{2×P×R}{P+R} = \frac{2×TP}{样例总数+TP-TN}=\frac{1}{\frac{1}{2}(\frac{1}{P} + \frac{1}{R})} = \frac{2TP}{TP+FP+TP+FN}
F1=P+R2×P×R=样例总数+TP−TN2×TP=21(P1+R1)1=TP+FP+TP+FN2TP
F
β
F_β
Fβ:F1度量的一般形式,能让我们表达出对查准率/查全率的不同偏好,这是加权调和平均
F
β
=
(
1
+
β
2
)
×
P
×
R
(
β
2
×
P
)
+
R
=
1
1
1
+
β
2
(
1
p
+
β
2
R
)
F_β = \frac{(1+ β^2)×P×R}{(β^2×P)+R} =\frac{1}{ \frac{1}{1+ β^2}(\frac{1}{p} + \frac{β^2}{R})}
Fβ=(β2×P)+R(1+β2)×P×R=1+β21(p1+Rβ2)1
β>0度量了查全率对查准率的相对重要性,β=1时退化为标准的F1;β>1时查全率有更大影响;β<1时查准率有更大的影响。
多分类
可以采用的方法:直接就有多种分类;采用多种二分类
n个二分类实现的多分类问题:
-
先分别计算,再求平均值
-
先再混淆矩阵上分别求除查准率和查全率,记为 ( P 1 , R 1 ) , ( P 2 , R 2 ) , . . . , ( P n , R n ) (P_1,R_1),(P_2,R_2),...,(P_n,R_n) (P1,R1),(P2,R2),...,(Pn,Rn),再求平均值。得到“宏查准率”(macro_P)、“宏查全率”(macro-R)、“宏F1”(macro-F1)
-
m a c r o − P = 1 n ∑ i = 1 n P i macro-P = \frac{1}{n}\sum_{i=1}^{n}P_i macro−P=n1i=1∑nPi
m a c r o − R = 1 n ∑ i = 1 n R i macro-R = \frac{1}{n}\sum_{i=1}^{n}R_i macro−R=n1i=1∑nRi
m a c r o − F 1 = 2 × m a c r o − P × m a c r o − R m a c r o − P + m a c r o − R macro-F1 = \frac{2×macro-P×macro-R}{macro-P+macro-R} macro−F1=macro−P+macro−R2×macro−P×macro−R
-
-
先平均再计算
-
先将各混淆矩阵的对应元素进行平均,得到 T P ‾ \overline{TP} TP、 F P ‾ \overline{FP} FP、 T N ‾ \overline{TN} TN、 F N ‾ \overline{FN} FN,再求出“微查准率”(micro-P),“微查全率”(micro-R),”微F1“(micro-F1)
-
m i c r o − P = T P ‾ T P ‾ + F P ‾ micro-P = \frac{\overline{TP}}{\overline{TP}+\overline{FP}} micro−P=TP+FPTP
-
m i c r o − R = T P ‾ T P ‾ + F N ‾ micro-R = \frac{\overline{TP}}{\overline{TP}+\overline{FN}} micro−R=TP+FNTP
-
m i c r o − F 1 = 2 × m i c r o − P × m i c r o − R m i c r o − P + m i c r o − R micro-F1 = \frac{2×micro-P×micro-R}{micro-P+micro-R} micro−F1=micro−P+micro−R2×micro−P×micro−R
-
上述是一种训练集上的一种算法,用什么样的指标评估好坏
2.3.3 ROC与AUC
接下来是一种训练集上多种算法:(不同算法之间比较应该怎么做)
P-R曲线在2.3.2中展示
很多学习器是为了测试样本产生一个实值或概率预测,然后将这个预测值与一个分类阈值进行比较,若大于阈值则为正例,否则为反例
eg:比如1-10,我定5为阈值,那么大于5的为正类,余下的为反类
ROC曲线
ROC全称”受试者工作特征“(Receiver Operating Characteristic)曲线。根据学习器的预测结果对样例进行排序,按此顺序逐个把样本作为正例进行预测,每次计算出两个重要量的值,分别以它们为横、纵坐标,得到ROC曲线。
这个实值或概率预测结果的好坏,决定了学习器的泛化能力。
纵轴是”真正例率“(TruePositive Rate,简称TPR):预测的真正例数和实际的正例数比值,有多少真正的正例预测准确;
横轴是”假正例率“(False Positive Rate,简称FPR):预测的假正例数和实际的反例数比值,有多少反例被预测为正例;
理想情况下,TPR接近1,FPR接近0
T
P
R
=
T
P
T
P
+
F
N
TPR=\frac{TP}{TP+FN}
TPR=TP+FNTP
F P R = F P T N + F P FPR=\frac{FP}{TN + FP} FPR=TN+FPFP
AUC(Area Under ROC Curve):ROC曲线下的面积
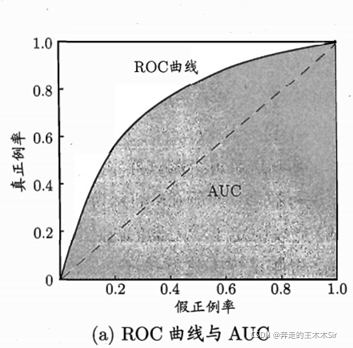
我们想的好的情况是真正例率增长的快就越好,好的越好(即在上图实线的上方再来一条线)
AUC
AUC(Area Under ROC Curve):ROC曲线下的面积
假定ROC曲线是由坐标为 ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) , {(x_1,y_1),(x_2,y_2),...,(x_m,y_m),} (x1,y1),(x2,y2),...,(xm,ym),的点按序连接而形成 ( x 1 = 0 , x m = 1 ) (x_1=0,x_m=1) (x1=0,xm=1)则可以形成下图
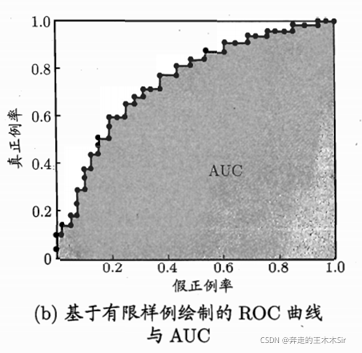
则AUC可估算为:
A
U
C
=
1
m
∑
i
=
1
m
−
1
(
x
i
+
1
−
x
i
)
(
y
i
+
y
i
+
1
)
AUC=\frac{1}{m}\sum_{i=1}^{m-1}(x_{i+1}-x_i)(y_i+y_{i+1})
AUC=m1i=1∑m−1(xi+1−xi)(yi+yi+1)
形式化的看,AUC考虑的是样本预测的排序质量,因此它与排序误差有紧密联系,给定
m
+
m^+
m+个正例和
m
−
m^-
m−个反例,令
D
+
D^+
D+和
D
−
D^-
D−分别表示正、反例集合,则排序“损失”(lose)定义为:
l
r
a
n
k
=
1
m
+
m
−
∑
x
+
∈
D
+
∑
x
−
∈
D
−
(
Ⅱ
(
f
(
x
+
)
<
f
(
x
−
)
)
+
1
2
Ⅱ
(
f
(
x
+
)
=
f
(
x
−
)
)
)
l_{rank} = \frac{1}{m^+m^-}\sum_{x^+∈D^+}\sum_{x^-∈D^-}(Ⅱ(f(x^+)<f(x^-))+\frac{1}{2}Ⅱ(f(x^+)=f(x^-)))
lrank=m+m−1x+∈D+∑x−∈D−∑(Ⅱ(f(x+)<f(x−))+21Ⅱ(f(x+)=f(x−)))
我们可以看到
l
r
a
n
k
l_{rank}
lrank对应的是ROC曲线之上的面积,若一个正例在ROC曲线上对应标记点的坐标为
(
x
,
y
)
(x,y)
(x,y),则x是排序在其之前的反例所占的比例,即假正比例率,
A
U
C
=
1
−
l
r
a
n
k
AUC=1-l_{rank}
AUC=1−lrank
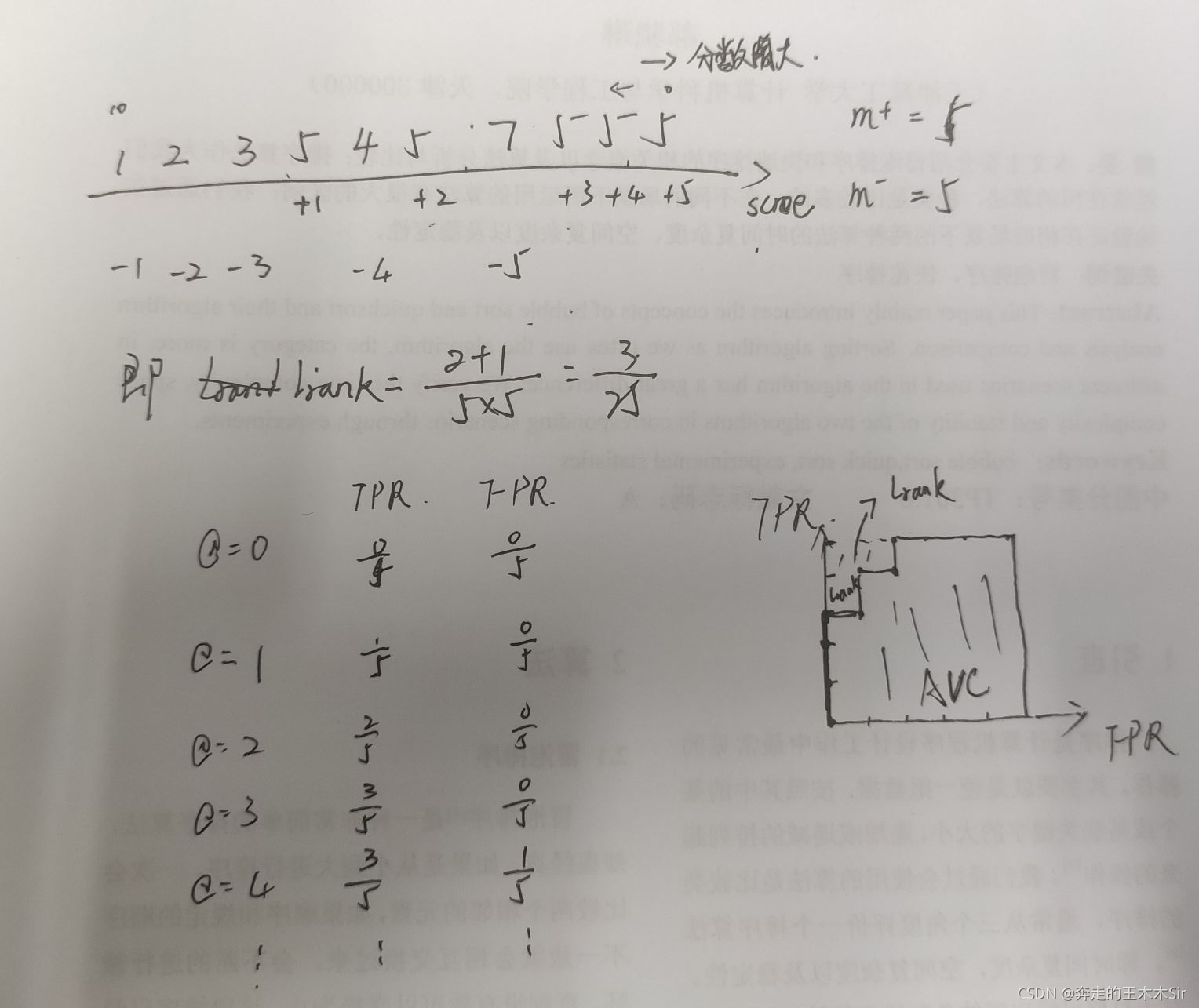
面 积 越 大 越 好 \textcolor{red}{面积越大越好} 面积越大越好
2.3.4 代价敏感错误率与代价曲线
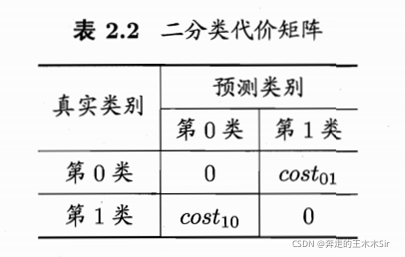
以二分类任务为例,设定一个“代价矩阵”(cost matrix),其中 c o s t i j cost_{ij} costij表示将第 i i i类样本预测为第 j j j类样本的代价。一般来说, c o s t i j = 0 cost_{ij} = 0 costij=0;若将第0类判别为第1类所造成损失更大,则 c o s t 01 > c o s t 10 cost_{01}>cost_{10} cost01>cost10;损失相差越大,则两值得差别越大。
之前的错误率是直接计算错误的次数,并没有考虑从不同错误会导致不同的后果。
在非等代价下,我们所希望的不再是简单地最小化错误次数,而是希望最小化“总体代价”(total cost)。
上图中,若我们把第0类作为正类,第1类作为反类,
D
+
D^+
D+为D的正例子集,
D
−
D^-
D−为D的反例子集,则可以得到如下代价敏感错误率的公式:
E
(
f
;
D
;
c
o
s
t
)
=
1
m
(
∑
x
i
∈
D
+
Ⅱ
(
f
(
x
i
)
≠
y
i
×
c
o
s
t
01
)
+
∑
x
i
∈
D
−
Ⅱ
(
f
(
x
i
)
≠
y
i
×
c
o
s
t
10
)
)
E(f;D;cost) = \frac{1}{m}(\sum_{x_i∈D^+}Ⅱ(f(x_i) ≠ y_i×cost_{01})+\sum_{x_i∈D^-}Ⅱ(f(x_i) ≠ y_i×cost_{10}))
E(f;D;cost)=m1(xi∈D+∑Ⅱ(f(xi)=yi×cost01)+xi∈D−∑Ⅱ(f(xi)=yi×cost10))
即得到的结果和真实的结果不一致的情况。
代价曲线
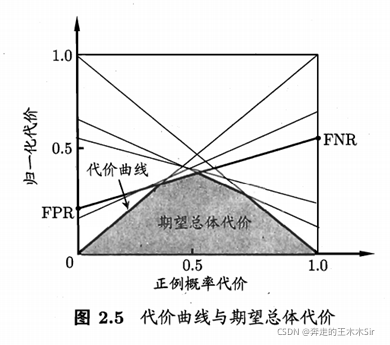
-
明确参数
p = m + /m
-
代价曲线基本思路
-
目的:对于一个模型,根据p不同,找到使得代价总期望最小的模型的阈值
-
横轴:归一化的整改率代价期望
P ( + ) c o s t = p × c o s t 01 p × c o s t 01 + ( 1 − p ) × c o s t 10 P(+)cost=\frac{p×cost_{01}}{p×cost_{01}+(1-p)×cost_{10}} P(+)cost=p×cost01+(1−p)×cost10p×cost01 -
纵轴:归一化的总代价期望
c o s t n o r m = F N R × p × c o s t 01 + F P R × ( 1 − p ) × c o s t 10 p × c o s t 01 + ( 1 − p ) × c o s t 10 cost_{norm}=\frac{FNR×p×cost_{01}+FPR×(1-p)×cost_{10}}{p×cost_{01}+(1-p)×cost_{10}} costnorm=p×cost01+(1−p)×cost10FNR×p×cost01+FPR×(1−p)×cost10
这里的 F N R = F N / ( T P + F N ) FNR=FN/(TP+FN) FNR=FN/(TP+FN), F P R = F P / ( F P + T N ) FPR=FP/(FP+TN) FPR=FP/(FP+TN) -
FNR:假负例率,即真实为正,测试为负的概率,FNR = 1 - TPR;
FPR:假正例率,即真实为负,测试为正的概率。
因为期望损失代价是由正例先验概率和混淆矩阵确定的,
当ROC曲线的阈值确定,则FPR和FNR也是确定的,
所以代价曲线是一条直线,且不同的代价对应不同的阈值
-
大致过程:
给定P,给定模型->根据归一化代价期望的最小值->确定圈1,2,3,4的比例->之前例子可以看出阈值确定了这个比例,反过来说,这个比例确定了,阈值也就确定了,所以该模型的阈值也对应确定下来,也正是模型固定下来了。–>模型的综合考量指标P,R,F1, F β F_β Fβ,等都确定了
-
-
绘制
ROC曲线上的每一点对应了代价平面上的一条线段,设ROC曲线上的点的坐标为(FPR,TPR),则可相应计算出FNR,然后再大家平面上绘制一条从(0,FPR)到(1,FNR)的线段,线段下的面积即表示了该条件下的期望总代价;如此将ROC曲线上的每个点转化为代价平面上的一条线段,然后取所有线段的下界,围成的面积即为在所有条件下学习器的期望总体代价。
2.4 比较检验
选择合适的评估方法和相应的性能度量,计算出性能度量后直接比较,这样的比较方式存在以下问题:
- 测试集上的性能与真正的泛化性能未必相同
- 测试集不同反映出来的性能不同
- 机器学习算法本身有一定的随机性,同一个测试集上多次运行,可能会有不同的结果
学习需要一定的概率论基础, 可以看一下课程概率论与数理统计【合集】【小元老师】这个课程是从考研的角度进行的,但是我们需要的是这个概率论的知识在工程角度上该怎么应用。
工程数学和概率论是非常重要的,好多数学在这里运用到,以后也会运用的。(PS:学完第二章,就麻溜的看概率论,昨天在图书馆借了一本概率论的书)
不同的测试集不同的算法采用的检验不同:
- 一种测试集一种算法:二项检验
- 多个测试集一种算法:2.4.1 t检验
- 多个测试集两种算法:2.4.2 交叉验证t检验
- 一个测试集两种算法:2.4.3 McNemar检验
- 多个测试集多种算法:2.4.4 Friedman检验和Nemenyi后续检验
常用的离散型随机变量
-
0-1分布
若随机变量X只有两个可能的取值0和1,其概率分布为
P ( X = x i ) = p x i ( 1 − p ) 1 − x i , x i = 0 , 1 P(X = x_i) = p ^ {x_i}(1-p)^{1-{x_i}},x_i=0,1 P(X=xi)=pxi(1−p)1−xi,xi=0,1
则称X服从0-1分布 -
二项分布 B=(n,p)
设事件A在任意一次实验中出现的概率都是P(0<p<1)。X表示n重伯努利试验中事件A发生的次数,则X所有可能的取值为0,1,2,…,n,且相应的该概率为
P ( X = k ) = C n k P k ( 1 − p ) n − k , k = 0 , 1 , 2 , . . . , n P(X=k)=C^k_nP^k(1-p)^{n-k},k=0,1,2,...,n P(X=k)=CnkPk(1−p)n−k,k=0,1,2,...,n
2.4.1 假设检验
泛化错误率为ε ,测试错误率为 ϵ ^ \widehat{\epsilon} ϵ ,共有m个样本。
泛化错误率为 ϵ \epsilon ϵ的学习器在一个样本上犯错的概率是 ϵ \epsilon ϵ;测试错误率 ϵ ^ \widehat{\epsilon} ϵ 意味着在m个测试样本中恰有 ϵ ^ × m \widehat{\epsilon}×m ϵ ×m个被误分类。
可得泛化错误率为ε的学习器被测得测试错误率为ε^的概率

P在
ϵ
=
ϵ
^
\epsilon =\widehat{\epsilon}
ϵ=ϵ
时最大,
∣
ϵ
−
ϵ
^
∣
|\epsilon -\widehat{\epsilon}|
∣ϵ−ϵ
∣增大时P减小,这符合二项分布。
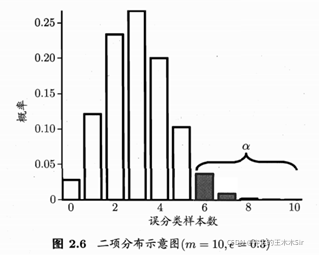
假设: ϵ < = ϵ 0 \epsilon <=\epsilon_0 ϵ<=ϵ0。显著度为:α。置信度为:1- α
在 1- α的概率内能观测到的最大错误率:

此时若测试错误率小于临界值,则可得结论:在α的显著度下,假设 ϵ < = ϵ 0 \epsilon <=\epsilon_0 ϵ<=ϵ0不能被拒绝,即能以1- α的置信度认为,学习器的泛化错误率不大于 ϵ 0 \epsilon_0 ϵ0。否则可被拒绝。
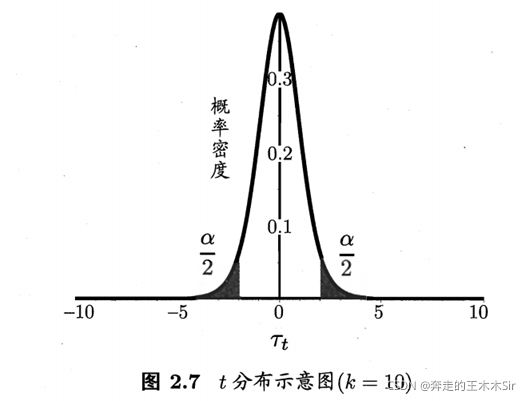
T检验
在很多时候我们并非仅做一次留出法估计,而是通过多次重复留出法或是交叉验证法等进行多次训练/测试,这样会得到多个测试错误率,此时我们可使用“t检验”(t-test)。加黑色我们得到了k个测试错误率,
ϵ
1
^
\widehat{\epsilon_1}
ϵ1
,
ϵ
2
^
\widehat{\epsilon_2}
ϵ2
,…,
ϵ
k
^
\widehat{\epsilon_k}
ϵk
,则平均测试错误率
μ
\mu
μ,和方差
σ
\sigma
σ。
μ
=
1
k
∑
i
=
1
k
ϵ
i
^
\mu=\frac{1}{k}\sum_{i=1}^{k}\widehat{\epsilon_i}
μ=k1i=1∑kϵi
σ 2 = 1 k − 1 ∑ i = 1 k ( ϵ i ^ − μ ) 2 \sigma^2=\frac{1}{k-1}\sum_{i=1}^{k}(\widehat{\epsilon_i}-\mu)^2 σ2=k−11i=1∑k(ϵi −μ)2
考虑这k个测试错误率可以看作泛化错误率
ϵ
0
\epsilon_0
ϵ0d的独立采样,则变量
τ
t
=
k
(
μ
−
ϵ
0
)
σ
\tau_t=\frac{\sqrt{k}(\mu-\epsilon_0)}{\sigma}
τt=σk(μ−ϵ0)
服从自由度为k-1的t分布,如图:
关于其他的比较检验,这里暂不说明了,因为我学的也不是很到位,后面几个用到的也比较少,所以如果有大佬们有想法,欢迎私信交流。
2.5 偏差与方差
bias-偏差
variance-方差
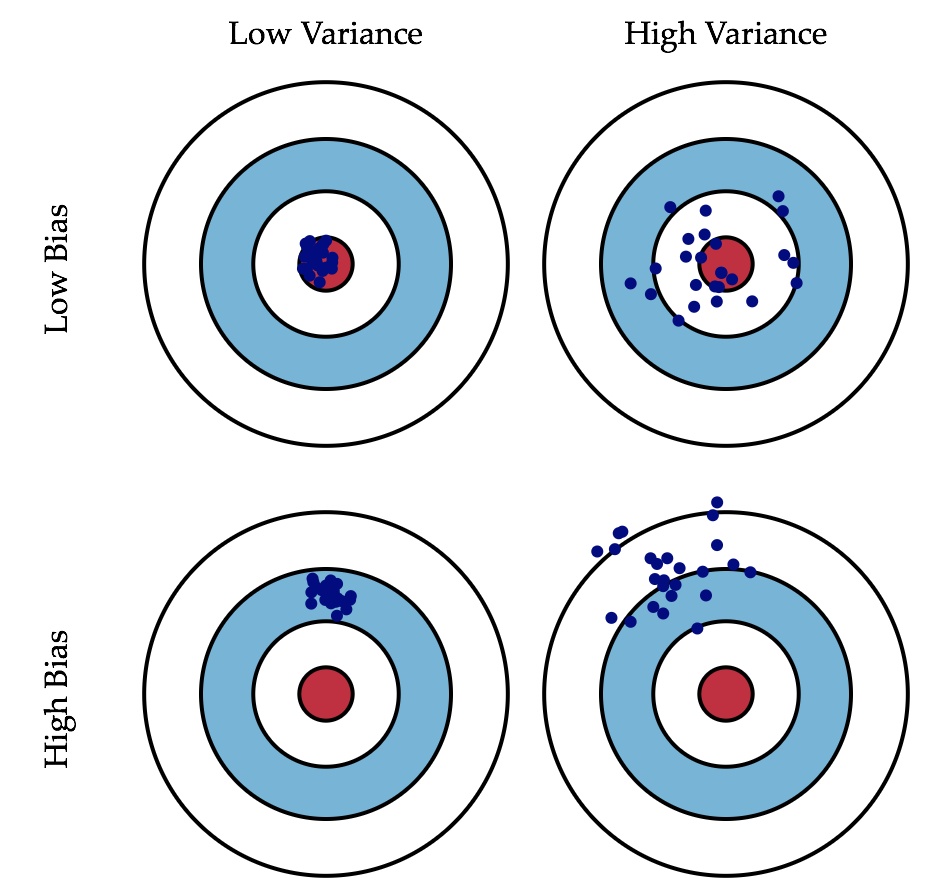
理解这个图就非常的nice了。
离红圈近,或者是分散开但是中心点还是在红色圈内,此时偏差较小。
分的很散,中心点也不在红圈内,方差很大。
那为什么训练的越好,方差和偏差都会很大呢?可以这样理解,训练的越好红圈会变得越来越小,此时之前的数据集就会远离。