
@Import解析
@Import提供了不同于@Bean的导入方式,本文将从用法和原理介绍这个由Spring提供的注解。
用法1:@Import+普通类
@Configuration
@Import(Teacher.class)
public class ImportConfig {}
public class Teacher {}
@Import引入一个普通类,可以将该类添加到Spring的单例池内。
用法2:@Import+实现了 ImportSelector的类
@Configuration
@Import(ComputerSelector.class)
public class ImportSelectorConfig {}
public class ComputerSelector implements ImportSelector {
@Override
public String[] selectImports(AnnotationMetadata importingClassMetadata) {
return new String[]{"com.slc.imp.selector.Computer"};
}
@Override
public Predicate<String> getExclusionFilter() {
return DeferredImportSelector.super.getExclusionFilter();
}
}
package com.slc.imp.selector;
public class Computer {}
@Import导入的类实现ImportSelector,可以通过selectImports指定需要导入的类的全类名,进而将类交给Spring管理。并且可以通过getExclusionFilter指定需要排除的部分。
用法3:@Import+实现了 ImportBeanDefinitionRegistrar的类
@Configuration
@Import(MyImportBeanDefinitionRegistrar.class)
public class ImportRegistrarConfig {}
public class MyImportBeanDefinitionRegistrar implements ImportBeanDefinitionRegistrar {
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry, BeanNameGenerator importBeanNameGenerator) {
AbstractBeanDefinition beanDefinition = BeanDefinitionBuilder.genericBeanDefinition(School.class).getBeanDefinition();
String beanName = importBeanNameGenerator.generateBeanName(beanDefinition, registry);
registry.registerBeanDefinition(beanName,beanDefinition);
}
@Override
public void registerBeanDefinitions(AnnotationMetadata importingClassMetadata, BeanDefinitionRegistry registry) {
}
}
public class School {}
@Import导入的类实现ImportBeanDefinitionRegistrar,该接口提供了两个可重写的方法。在两个方法内可以获取到Spring的BeanDefinitionRegistry,通过该类可以手动注入BeanDefinition,然后交给Spring去初始化BeanDefinition,进而将需要注入的类添加到Spring容器中。
两个方法区别不大,区别在于可以使用BeanNameGenerator生成beanName,或者也可以自己指定需要注入的类对应的名。获取的时候使用ByName方式即可。
用法4:@Import与ImportAware
首先定义一个注解,并使用@Import标注
@Retention(RetentionPolicy.RUNTIME)@Import(SpecialConfigurationAware.class)public @interface EnableAnnotation { String value() default "";}
编写类并实现ImportAware接口
public class SpecialConfigurationAware implements ImportAware { private String value; @Override public void setImportMetadata(AnnotationMetadata importMetadata) { Map<String, Object> annotationAttributes = importMetadata.getAnnotationAttributes(EnableAnnotation.class.getName()); value= annotationAttributes.get("value"); System.out.println(); } @Bean public Foo foo() { return new Foo(this.value); }}
在任意一个配置类引入自定义注解
@Configuration@EnableAnnotation("appconfig1111")public class AwareConfiguration {}
这种方法可以获取到自定义注解标注的类上面的所有注解信息,在本例中即可以获取到AwareConfiguration类上面的所有注解信息。
比如@EnableAsync导入的类AsyncConfigurationSelector,里面就获取了对应注解的元信息。
解析原理
Spring加载的过程大概可以分为两个部分:解析各类Bean信息并转换成对应的BeanDefinition,加载BeanDefinition完成初始化并添加到Spring单例池中。
以注解式启动Spring为了,解析的过程即为扫描包下的各个注解,获取对应的类,封装成BeanDefinition,本文主要分析一下 “解析”这一过程。
首先是扫描,Spring是在refresh#invokeBeanFactoryPostProcessors 里面完成扫描的过程的。
invokeBeanFactoryPostProcessors
protected void invokeBeanFactoryPostProcessors(ConfigurableListableBeanFactory beanFactory) { PostProcessorRegistrationDelegate.invokeBeanFactoryPostProcessors(beanFactory, getBeanFactoryPostProcessors()); if (beanFactory.getTempClassLoader() == null && beanFactory.containsBean(LOAD_TIME_WEAVER_BEAN_NAME)) { beanFactory.addBeanPostProcessor(new LoadTimeWeaverAwareProcessor(beanFactory)); beanFactory.setTempClassLoader(new ContextTypeMatchClassLoader(beanFactory.getBeanClassLoader())); }}
委托给PostProcessorRegistrationDelegate完成BeanFactoryPostProcessors的调用。
完整代码不多贴了。这里贴一下重要部分的代码。
public static void invokeBeanFactoryPostProcessors( ConfigurableListableBeanFactory beanFactory, List<BeanFactoryPostProcessor> beanFactoryPostProcessors) { ... ... List<BeanDefinitionRegistryPostProcessor> currentRegistryProcessors = new ArrayList<>(); // 1.首先,调用实现 PriorityOrdered 的 BeanDefinitionRegistryPostProcessors。 String[] postProcessorNames = beanFactory.getBeanNamesForType(BeanDefinitionRegistryPostProcessor.class, true, false); for (String ppName : postProcessorNames) { if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { //获取BeanDefinitionRegistryPostProcessor 接口定义的类, //Spring内部定义的扫描类,优先级高于 BeanFactoryPostProcessor,为 BeanFactoryPostProcessor的子类 currentRegistryProcessors.add(beanFactory.getBean(ppName, BeanDefinitionRegistryPostProcessor.class)); processedBeans.add(ppName); } } sortPostProcessors(currentRegistryProcessors, beanFactory); registryProcessors.addAll(currentRegistryProcessors); //调用处理器,完成扫描 invokeBeanDefinitionRegistryPostProcessors(currentRegistryProcessors, registry); ... ... String[] postProcessorNames =beanFactory.getBeanNamesForType(BeanFactoryPostProcessor.class, true, false); List<BeanFactoryPostProcessor> priorityOrderedPostProcessors = new ArrayList<>(); List<String> orderedPostProcessorNames = new ArrayList<>(); List<String> nonOrderedPostProcessorNames = new ArrayList<>(); for (String ppName : postProcessorNames) { if (processedBeans.contains(ppName)) { /** * skip - already processed in first phase above * 已经先调用完毕了,比如ConfigurationClassPostProcessor,该类实现了 BeanDefinitionRegistryPostProcessor 接口 * 而BeanDefinitionRegistryPostProcessor是 BeanFactoryPostProcessor的子类,所以这个集合里面还是会得到该类的名称, * 所以此处跳过(不做处理) */ } else if (beanFactory.isTypeMatch(ppName, PriorityOrdered.class)) { priorityOrderedPostProcessors.add(beanFactory.getBean(ppName, BeanFactoryPostProcessor.class)); } else if (beanFactory.isTypeMatch(ppName, Ordered.class)) { orderedPostProcessorNames.add(ppName); } else { nonOrderedPostProcessorNames.add(ppName); } } List<BeanFactoryPostProcessor> nonOrderedPostProcessors = new ArrayList<>(nonOrderedPostProcessorNames.size()); for (String postProcessorName : nonOrderedPostProcessorNames) { nonOrderedPostProcessors.add(beanFactory.getBean(postProcessorName, BeanFactoryPostProcessor.class)); } invokeBeanFactoryPostProcessors(nonOrderedPostProcessors, beanFactory); ... ...}
- 分别按优先级调用
BeanDefinitionRegistryPostProcessor和BeanFactoryPostProcessor接口的处理器。 - 前者为后者的子类,两个接口都算是工厂级别的处理器,实现
BeanDefinitionRegistryPostProcessor类会被最早调用,
从名字不难得出,Spring的本意是想先调用负责注册BeanDefinition的处理器,然后再调用别的工厂处理器。并且Spring在源码里面也标注了如果需要扩展的话,建议实现BeanFactoryPostProcessor,而不是BeanDefinitionRegistryPostProcessor。
private static void invokeBeanDefinitionRegistryPostProcessors( Collection<? extends BeanDefinitionRegistryPostProcessor> postProcessors, BeanDefinitionRegistry registry) { for (BeanDefinitionRegistryPostProcessor postProcessor : postProcessors) { postProcessor.postProcessBeanDefinitionRegistry(registry); } }
我们来看扫描部分的代码,在前文关于Spring的启动流程里面有说过,Spring最早的时候会注册五到六个内部用的Bean,其中一个就用到了这里。在整个扫描阶段第一个被使用的BeanFactory处理器是ConfigurationClassPostProcessor
postProcessBeanDefinitionRegistry
public class ConfigurationClassPostProcessor implements BeanDefinitionRegistryPostProcessor, PriorityOrdered, ResourceLoaderAware, BeanClassLoaderAware, EnvironmentAware {...... @Override public void postProcessBeanDefinitionRegistry(BeanDefinitionRegistry registry) { int registryId = System.identityHashCode(registry); if (this.registriesPostProcessed.contains(registryId)) { throw new IllegalStateException( "postProcessBeanDefinitionRegistry already called on this post-processor against " + registry); } if (this.factoriesPostProcessed.contains(registryId)) { throw new IllegalStateException( "postProcessBeanFactory already called on this post-processor against " + registry); } this.registriesPostProcessed.add(registryId); processConfigBeanDefinitions(registry); }...... @Override public int getOrder() { return Ordered.LOWEST_PRECEDENCE; }}
同时实现了BeanDefinitionRegistryPostProcessor和PriorityOrdered,并且优先级数值为Ordered.LOWEST_PRECEDENC即Integer.MAX_VALUE,就是为了确保这是第一个被调用了,可想而知其中重要性。在这个处理器内部Spring完成了配置类的解析。继续关键部分代码。
processConfigBeanDefinitions
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) { List<BeanDefinitionHolder> configCandidates = new ArrayList<>(); String[] candidateNames = registry.getBeanDefinitionNames(); for (String beanName : candidateNames) { BeanDefinition beanDef = registry.getBeanDefinition(beanName); if (beanDef.getAttribute(ConfigurationClassUtils.CONFIGURATION_CLASS_ATTRIBUTE) != null) { if (logger.isDebugEnabled()) { logger.debug("Bean definition has already been processed as a configuration class: " + beanDef); } } // 检查是否是一个配置类, // 如果加了@Configuration,那么对应的BeanDefinition为full; // 如果加了@Bean,@Component,@ComponentScan,@Import,@ImportResource这些注解,则为lite。 else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory)) { configCandidates.add(new BeanDefinitionHolder(beanDef, beanName)); } } // Return immediately if no @Configuration classes were found if (configCandidates.isEmpty()) { return; } // Sort by previously determined @Order value, if applicable configCandidates.sort((bd1, bd2) -> { int i1 = ConfigurationClassUtils.getOrder(bd1.getBeanDefinition()); int i2 = ConfigurationClassUtils.getOrder(bd2.getBeanDefinition()); return Integer.compare(i1, i2); }); // Detect any custom bean name generation strategy supplied through the enclosing application context SingletonBeanRegistry sbr = null; if (registry instanceof SingletonBeanRegistry) { sbr = (SingletonBeanRegistry) registry; if (!this.localBeanNameGeneratorSet) { BeanNameGenerator generator = (BeanNameGenerator) sbr.getSingleton( AnnotationConfigUtils.CONFIGURATION_BEAN_NAME_GENERATOR); if (generator != null) { this.componentScanBeanNameGenerator = generator; this.importBeanNameGenerator = generator; } } } if (this.environment == null) { this.environment = new StandardEnvironment(); } // Parse each @Configuration class ConfigurationClassParser parser = new ConfigurationClassParser( this.metadataReaderFactory, this.problemReporter, this.environment, this.resourceLoader, this.componentScanBeanNameGenerator, registry); Set<BeanDefinitionHolder> candidates = new LinkedHashSet<>(configCandidates); Set<ConfigurationClass> alreadyParsed = new HashSet<>(configCandidates.size()); do { parser.parse(candidates); parser.validate(); Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses()); configClasses.removeAll(alreadyParsed); // Read the model and create bean definitions based on its content if (this.reader == null) { this.reader = new ConfigurationClassBeanDefinitionReader( registry, this.sourceExtractor, this.resourceLoader, this.environment, this.importBeanNameGenerator, parser.getImportRegistry()); } this.reader.loadBeanDefinitions(configClasses); alreadyParsed.addAll(configClasses); candidates.clear(); if (registry.getBeanDefinitionCount() > candidateNames.length) { String[] newCandidateNames = registry.getBeanDefinitionNames(); Set<String> oldCandidateNames = new HashSet<>(Arrays.asList(candidateNames)); Set<String> alreadyParsedClasses = new HashSet<>(); for (ConfigurationClass configurationClass : alreadyParsed) { alreadyParsedClasses.add(configurationClass.getMetadata().getClassName()); } for (String candidateName : newCandidateNames) { if (!oldCandidateNames.contains(candidateName)) { BeanDefinition bd = registry.getBeanDefinition(candidateName); if (ConfigurationClassUtils.checkConfigurationClassCandidate(bd, this.metadataReaderFactory) && !alreadyParsedClasses.contains(bd.getBeanClassName())) { candidates.add(new BeanDefinitionHolder(bd, candidateName)); } } } candidateNames = newCandidateNames; } } while (!candidates.isEmpty()); // Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) { sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry()); } if (this.metadataReaderFactory instanceof CachingMetadataReaderFactory) { // Clear cache in externally provided MetadataReaderFactory; this is a no-op // for a shared cache since it'll be cleared by the ApplicationContext. ((CachingMetadataReaderFactory) this.metadataReaderFactory).clearCache(); }}
这个方法里面主要是两行代码:
parser.parse(candidates):创建一个解析器,让parser 解析 candidates,获取配置类,并标注每个配置类的信息。this.reader.loadBeanDefinitions(configClasses):加载配置类,包含@Import,@ImportResource等资源的处理。
在解析对应包下的各个注解后,Spring会封装成ConfigurationClass,并且通过do while语句,不断比对当前已经解析的配置类和新的配置类,确保每次解析完成的ConfiguartionClass不会再引进新的配置类。最终将所有的的配置类解析完毕。
parser.parse(candidates)
点进parse方法看Spring是如何解析的。
public void parse(Set<BeanDefinitionHolder> configCandidates) { for (BeanDefinitionHolder holder : configCandidates) { BeanDefinition bd = holder.getBeanDefinition(); try { if (bd instanceof AnnotatedBeanDefinition) { parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName()); } else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) { parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName()); } else { parse(bd.getBeanClassName(), holder.getBeanName()); } } catch (BeanDefinitionStoreException ex) { throw ex; } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex); } } this.deferredImportSelectorHandler.process();}
在上一个方法里面的else if (ConfigurationClassUtils.checkConfigurationClassCandidate(beanDef, this.metadataReaderFactory))会判断当前BeanDefinitionNames对应的类是否是配置类。在最开始的时候,BeanDefnitionNames只有Spring内部自己注册的BeanDefinition以外,就是我们手动传的AppConfig,实际上也只有这个类会进行的之后的流程。因为最开始的时候只有AppConfig是配置类。因为AppConfig标注了@Configuration。
protected final void parse(AnnotationMetadata metadata, String beanName) throws IOException { processConfigurationClass(new ConfigurationClass(metadata, beanName), DEFAULT_EXCLUSION_FILTER);}
由于是注解式启动,AppConfig对应的BeanDefinition自然属于AnnotatedBeanDefinition。继续跟进,跳过不重要的地方。最终进入到doProcessConfigurationClass方法。
doProcessConfigurationClass
protected final SourceClass doProcessConfigurationClass( ConfigurationClass configClass, SourceClass sourceClass, Predicate<String> filter) throws IOException { if (configClass.getMetadata().isAnnotated(Component.class.getName())) { // Recursively process any member (nested) classes first processMemberClasses(configClass, sourceClass, filter); } // Process any @PropertySource annotations for (AnnotationAttributes propertySource : AnnotationConfigUtils.attributesForRepeatable( sourceClass.getMetadata(), PropertySources.class, org.Springframework.context.annotation.PropertySource.class)) { if (this.environment instanceof ConfigurableEnvironment) { processPropertySource(propertySource); } else { logger.info("Ignoring @PropertySource annotation on [" + sourceClass.getMetadata().getClassName() + "]. Reason: Environment must implement ConfigurableEnvironment"); } } // 处理 @ComponentScan 注解 Set<AnnotationAttributes> componentScans = AnnotationConfigUtils.attributesForRepeatable( sourceClass.getMetadata(), ComponentScans.class, ComponentScan.class); if (!componentScans.isEmpty() && !this.conditionEvaluator.shouldSkip(sourceClass.getMetadata(), ConfigurationPhase.REGISTER_BEAN)) { for (AnnotationAttributes componentScan : componentScans) { // The config class is annotated with @ComponentScan -> perform the scan immediately Set<BeanDefinitionHolder> scannedBeanDefinitions = this.componentScanParser.parse(componentScan, sourceClass.getMetadata().getClassName()); // Check the set of scanned definitions for any further config classes and parse recursively if needed for (BeanDefinitionHolder holder : scannedBeanDefinitions) { BeanDefinition bdCand = holder.getBeanDefinition().getOriginatingBeanDefinition(); if (bdCand == null) { bdCand = holder.getBeanDefinition(); } if (ConfigurationClassUtils.checkConfigurationClassCandidate(bdCand, this.metadataReaderFactory)) { parse(bdCand.getBeanClassName(), holder.getBeanName()); } } } } // 处理 @Import annotations processImports(configClass, sourceClass, getImports(sourceClass), filter, true); // Process any @ImportResource annotations AnnotationAttributes importResource = AnnotationConfigUtils.attributesFor(sourceClass.getMetadata(), ImportResource.class); if (importResource != null) { String[] resources = importResource.getStringArray("locations"); Class<? extends BeanDefinitionReader> readerClass = importResource.getClass("reader"); for (String resource : resources) { String resolvedResource = this.environment.resolveRequiredPlaceholders(resource); configClass.addImportedResource(resolvedResource, readerClass); } } // 处理 @Bean Set<MethodMetadata> beanMethods = retrieveBeanMethodMetadata(sourceClass); for (MethodMetadata methodMetadata : beanMethods) { configClass.addBeanMethod(new BeanMethod(methodMetadata, configClass)); } // Process default methods on interfaces processInterfaces(configClass, sourceClass); // Process superclass, if any if (sourceClass.getMetadata().hasSuperClass()) { String superclass = sourceClass.getMetadata().getSuperClassName(); if (superclass != null && !superclass.startsWith("java") && !this.knownSuperclasses.containsKey(superclass)) { this.knownSuperclasses.put(superclass, configClass); // Superclass found, return its annotation metadata and recurse return sourceClass.getSuperClass(); } } // No superclass -> processing is complete return null;}
- 解析
@PropertySource注解; - 配置类包含
@ComponentScan时,解析@ComponentScan,并对@ComponentScan标注的扫描路径进行解析(会不断递归,如果再次发现@ComponentScan,会再次重复扫描) - 解析
@Import - 解析
@ImportResource - 解析
@Bean - 解析接口上的默认方法(支持jdk8的新特性:接口可以定义default方法,Spring支持使用@Bean标注接口的default方法来注入Bean)
processImports(configClass, sourceClass, getImports(sourceClass), filter, true)
在processImports方法内解析@Import,这里有一个需要注意的点:getImports,在进入processImports前,会先调用getImports方法。
这个方法的逻辑非常简单:递归获取当前配置类上面的所有注解,包括注解的元注解,
private void processImports(ConfigurationClass configClass, SourceClass currentSourceClass, Collection<SourceClass> importCandidates, Predicate<String> exclusionFilter, boolean checkForCircularImports) { if (importCandidates.isEmpty()) { return; } if (checkForCircularImports && isChainedImportOnStack(configClass)) { this.problemReporter.error(new CircularImportProblem(configClass, this.importStack)); } else { this.importStack.push(configClass); try { for (SourceClass candidate : importCandidates) { if (candidate.isAssignable(ImportSelector.class)) { // Candidate class is an ImportSelector -> delegate to it to determine imports Class<?> candidateClass = candidate.loadClass(); //反射获取@Import导入的类 ImportSelector selector = ParserStrategyUtils.instantiateClass(candidateClass, ImportSelector.class, this.environment, this.resourceLoader, this.registry); Predicate<String> selectorFilter = selector.getExclusionFilter(); if (selectorFilter != null) { exclusionFilter = exclusionFilter.or(selectorFilter); } if (selector instanceof DeferredImportSelector) { this.deferredImportSelectorHandler.handle(configClass, (DeferredImportSelector) selector); } else { String[] importClassNames = selector.selectImports(currentSourceClass.getMetadata()); Collection<SourceClass> importSourceClasses = asSourceClasses(importClassNames, exclusionFilter); processImports(configClass, currentSourceClass, importSourceClasses, exclusionFilter, false); } } else if (candidate.isAssignable(ImportBeanDefinitionRegistrar.class)) { // Candidate class is an ImportBeanDefinitionRegistrar -> // delegate to it to register additional bean definitions Class<?> candidateClass = candidate.loadClass(); ImportBeanDefinitionRegistrar registrar = ParserStrategyUtils.instantiateClass(candidateClass, ImportBeanDefinitionRegistrar.class, this.environment, this.resourceLoader, this.registry); configClass.addImportBeanDefinitionRegistrar(registrar, currentSourceClass.getMetadata()); } else { // Candidate class not an ImportSelector or ImportBeanDefinitionRegistrar -> // process it as an @Configuration class this.importStack.registerImport( currentSourceClass.getMetadata(), candidate.getMetadata().getClassName()); MultiValueMap<String, AnnotationMetadata> imports = this.importStack.getImports(); System.out.println(imports); processConfigurationClass(candidate.asConfigClass(configClass), exclusionFilter); } } } catch (BeanDefinitionStoreException ex) { throw ex; } catch (Throwable ex) { throw new BeanDefinitionStoreException( "Failed to process import candidates for configuration class [" + configClass.getMetadata().getClassName() + "]", ex); } finally { this.importStack.pop(); } }}
我们可以看到处理@Import是,Spring会对其导入的类做以下几种判断:
- 是否实现了
ImportSelector,以及是否更进一步实现了DeferredImportSelector,(DeferredImportSelector是ImportSelector的子接口,有延迟加载的左右,主要是加载时机的不同。后面会更进一步解析这一部分的处理) - 是否实现了
ImportBeanDefinitionRegistrar - 都没有实现,此时作为普通类进行处理;
整理一下processImports干了些什么:
- 先通过
getImports获取当前配置类的@Import导入的类,即@Import的value值; - 通过
importStack这一属性进行配置类循环依赖的判断,如果不存在配置类的循环依赖,则继续解析(后面会说明如何进行的判断) - 因为@Import可以导入多个类,所以循环处理
importCandidates - 判断导入类,如果导入类实现了
ImportSelector,先反射获取@Import引入的类; - 如果该类没有实现
DeferredImportSelector,则直接调用selectImports,获取@Import引入的类指定的全限定类名的数组(真正引入的类),封装该类作为配置类; - 递归调用
processImports解析该配置类,因为导入的配置类(真正引入的类)可能继续实现了ImportSelector或者ImportBeanDefinitionRegistrar或者是一个使用了@Bean的配置类,所以需要递归。 - 如果实现了
DeferredImportSelector,则会将真正引入的类存放到deferredImportSelectors集合里面,暂时不做处理 - 如果实现了
ImportBeanDefinitionRegistrar,则存放到importBeanDefinitionRegistrars集合里面 - 解析完毕
上面讲述的过程比较晦涩,主要是在解析的过程内会出现很多递归的情况,需要结合代码多看一下。
解析了@Import之后,会接着解析@ImportResource、@Bean、接口默认方法。
回到parser.parse(candidates)
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
this.deferredImportSelectorHandler.process();
}
此时调用之前所有实现了deferredImportSelector接口类,再执行一遍都processImports操作
回到processConfigBeanDefinitions
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry) {
...
...
parser.parse(candidates);
parser.validate();
Set<ConfigurationClass> configClasses = new LinkedHashSet<>(parser.getConfigurationClasses());
configClasses.removeAll(alreadyParsed);
// Read the model and create bean definitions based on its content
if (this.reader == null) {
this.reader = new ConfigurationClassBeanDefinitionReader(
registry, this.sourceExtractor, this.resourceLoader, this.environment,
this.importBeanNameGenerator, parser.getImportRegistry());
}
this.reader.loadBeanDefinitions(configClasses);
...
...
}
最终回到parser.parse(candidates)方法,此时所有的@Import全部解析完毕
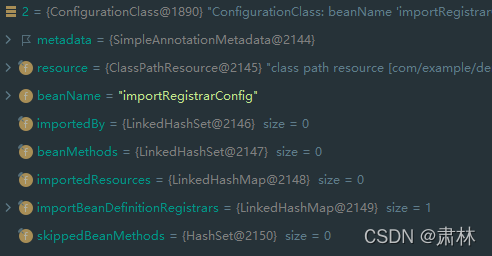
调用parse.parse其实只是各个注解的解析操作,主要是为ConfigClass设置属性,并没有完全加载成BeanDefinition(部分配置类会先加载到BeanDefinitonMap中)
- 比如这个配置类如果是被@Import导入的,则属性:
importedBy标注是被哪个配置类引入的, - 比如这个配置类如果有
@Bean注解,则属性:beanMethods就会指明有哪些方法。 - 比如这个配置类是@Import,而@Import导入的类实现的是
ImportBeanDefinitionRegistrar,则属性:importBeanDefinitionRegistrars就是哪个实现了ImportBeanDefinitionRegistrar的类
loadBeanDefinitions
public void loadBeanDefinitions(Set<ConfigurationClass> configurationModel) {
TrackedConditionEvaluator trackedConditionEvaluator = new TrackedConditionEvaluator();
for (ConfigurationClass configClass : configurationModel) {
loadBeanDefinitionsForConfigurationClass(configClass, trackedConditionEvaluator);
}
}
private void loadBeanDefinitionsForConfigurationClass(
ConfigurationClass configClass, TrackedConditionEvaluator trackedConditionEvaluator) {
if (trackedConditionEvaluator.shouldSkip(configClass)) {
String beanName = configClass.getBeanName();
if (StringUtils.hasLength(beanName) && this.registry.containsBeanDefinition(beanName)) {
this.registry.removeBeanDefinition(beanName);
}
this.importRegistry.removeImportingClass(configClass.getMetadata().getClassName());
return;
}
if (configClass.isImported()) {
registerBeanDefinitionForImportedConfigurationClass(configClass);
}
for (BeanMethod beanMethod : configClass.getBeanMethods()) {
loadBeanDefinitionsForBeanMethod(beanMethod);
}
loadBeanDefinitionsFromImportedResources(configClass.getImportedResources());
loadBeanDefinitionsFromRegistrars(configClass.getImportBeanDefinitionRegistrars());
}
调用this.reader.loadBeanDefinitions(configClasses),此时才会处理所有注解对应的操作,即加载到BeanDefinitionMap中。
注解式@Import:为导入类做一个开关
这块儿内容的标题不知道怎么取,总的来说就是@Import的一个特别用法,但是用的非常多。在Spring的源码里面我们可以看见很多@EnableXXX的注解。当使用这个注解时就会导入一些类到Spring单例池(容器)中。如果不用该注解就不会导入。
很多文章以及文章的评论里面都出现过这样一段内容:“当@Import作为元注解修饰其他注解的时候,到底需不要需不需要加@Configuration”
我的看法是 不需要。
为了说清楚这个东西,有一个方法需要再强调一下:getImports:Spring在扫描一个配置类时,会递归判断该配置类上面的所有元注解。
使用@EnableXXX时,往往@EnableXXX标注的类也被@Configuration标注,这两个注解通常是一起用的。因为getImports所以@EnableXXX里面的@Import也可以被解析到。
关于DeferredImportSelector的作用
起延迟加载的作用,普通的ImportSelector早早就被解析成ConfigurationClass,添加到ConfigurationClassParser的configurationClasses里面。直到所有的配置类都被解析完毕后,才会调用存储DeferredImportSelector的集合,然后循环处理。
public void parse(Set<BeanDefinitionHolder> configCandidates) {
for (BeanDefinitionHolder holder : configCandidates) {
BeanDefinition bd = holder.getBeanDefinition();
try {
if (bd instanceof AnnotatedBeanDefinition) {
parse(((AnnotatedBeanDefinition) bd).getMetadata(), holder.getBeanName());
}
else if (bd instanceof AbstractBeanDefinition && ((AbstractBeanDefinition) bd).hasBeanClass()) {
parse(((AbstractBeanDefinition) bd).getBeanClass(), holder.getBeanName());
}
else {
parse(bd.getBeanClassName(), holder.getBeanName());
}
}
catch (BeanDefinitionStoreException ex) {
throw ex;
}
catch (Throwable ex) {
throw new BeanDefinitionStoreException(
"Failed to parse configuration class [" + bd.getBeanClassName() + "]", ex);
}
}
//所有配置类都解析完了,才会调用它
this.deferredImportSelectorHandler.process();
}
简单来说,和ImportSelector的区别就是加载时机不同。
ImportSelector是在解析任意一个配置类都会进行的判断,属于解析配置类的 进行时状态;DeferredImportSelector则是所有配置类解析完毕才解析,属于解析配置类的 最后状态;
光说区别,不说应用场景是耍流氓。
应用场景:SpringBoot的默认配置类。
SpringBoot在引入各个starter的时候,会默认给程序员导入许多基础类,如果程序员没有重新定义基础类的话,那么直接使用starter里面提供的基础类即可。
SpringBoot就是通过DeferredImportSelector做到这一点的(除此之外,还要加上@Condition)
参看starter里面的各个默认配置类,会发现大量的@Condition,该注解的作用是判断单例池中是否已经存在程序员自己定义的Bean时,如果已经存在,就不再加载该starter的默认配置类。
但是有一个问题是:如何确保 程序员定义的类注册进单例池的时间 一定早于starter提供的配置呢?
换个角度:如何确保starter提供的配置的注册时间一定晚于程序员定义的类?
Map<ConfigurationClass, ConfigurationClass> configurationClasses = new LinkedHashMap<>()
因为DeferredImportSelector是最后被解析出来的配置类,他是最后添加进配置类的map集合当中的。而这个map集合,它是有序的。
所以程序员定义的Bean总是早于DeferredImportSelector被解析为ConfigurationClass,进而更早的解析成BeanDefiniton,进而更早的注册到spring单例池中(一级缓存)
配置文件的循环依赖时如何产生和解决的?
即processImports里面调用的一个方法:isChainedImportOnStack是如何作用的。
先说一下配置文件的循环依赖是如何产生的:(之所以强调 是配置文件的循环依赖,是为了区分自动装载的循环依赖)
比如:
@Configuration
@Import(ConfiguationB.class)
public class ConfiguationA {
}
@Configuration
@Import(ConfiguationC.class)
public class ConfiguationB {
}
@Configuration
@Import(ConfiguationA.class)
public class ConfiguationC {
}
像这种情况,配置A引入配置B,配置B引入配置C,配置C引入A,这样就构造了循环,解析的时候就会出现问题(会不断递归),甚至A配置类Imoprt本身类,也会问题。
解决方法:存储到ConfigurationClassParser的ImportStack中,借由这个类进行判断。
点进ImportStack这个类:
private static class ImportStack extends ArrayDeque<ConfigurationClass> implements ImportRegistry {
private final MultiValueMap<String, AnnotationMetadata> imports = new LinkedMultiValueMap<>();
...
}
可以知道这是一个双端队列。并且内部维护一个MultiValueMap
从解析第一个配置类开始,每次解析@Import是都先将当前被解析的配置类添加到importStack的map中。
this.importStack.registerImport(
currentSourceClass.getMetadata(), candidate.getMetadata().getClassName());
以上面的情况作为例子:
- 解析A,将B类添加到
importStack的map中,调用processConfigurationClass解析B类, - 解析B,将C类添加到
importStack的map中,调用processConfigurationClass解析C类, - 解析C,将A类添加到
importStack的map中,调用processConfigurationClass解析C类,此时isChainedImportOnStack将会判断发生了循环依赖
private boolean isChainedImportOnStack(ConfigurationClass configClass) {
if (this.importStack.contains(configClass)) {
String configClassName = configClass.getMetadata().getClassName();
AnnotationMetadata importingClass = this.importStack.getImportingClassFor(configClassName);
while (importingClass != null) {
if (configClassName.equals(importingClass.getClassName())) {
return true;
}
importingClass = this.importStack.getImportingClassFor(importingClass.getClassName());
}
}
return false;
}
这个方法的判断逻辑很简单:判断当前解析的配置类是否已经出现在了importStack的map中,如果已经出现了,则证明出现了循环依赖。
简单总结一下原理:通过一个map来存放已经做过处理的配置类,如果递归解析的某个阶段发现当前处理的配置类已经被解析了,那么就是发生了循环依赖。
ImportAware的原理
ImportAware的解析原理并不在processImports方法中,它是通过spring的后置处理器解决的。
首先是在调用postProcessBeanFactory的时候,spring会注册ImportAwareBeanPostProcessor,这个后置处理器就是用来处理ImportAware的。
@Override
public void postProcessBeanFactory(ConfigurableListableBeanFactory beanFactory) {
int factoryId = System.identityHashCode(beanFactory);
if (this.factoriesPostProcessed.contains(factoryId)) {
throw new IllegalStateException(
"postProcessBeanFactory already called on this post-processor against " + beanFactory);
}
this.factoriesPostProcessed.add(factoryId);
if (!this.registriesPostProcessed.contains(factoryId)) {
// BeanDefinitionRegistryPostProcessor hook apparently not supported...
// Simply call processConfigurationClasses lazily at this point then.
processConfigBeanDefinitions((BeanDefinitionRegistry) beanFactory);
}
//对Configuration类进行增强
enhanceConfigurationClasses(beanFactory);
//添加 ImportAwareBeanPostProcessor 后置处理器,用来支持ImportAware的解析,
beanFactory.addBeanPostProcessor(new ImportAwareBeanPostProcessor(beanFactory));
}
调用后置处理器
protected Object initializeBean(String beanName, Object bean, @Nullable RootBeanDefinition mbd) {
...
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
...
}
public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName)
throws BeansException {
Object result = existingBean;
//getBeanPostProcessors()会获取到之前添加的ImportAwareBeanPostProcessor
for (BeanPostProcessor processor : getBeanPostProcessors()) {
Object current = processor.postProcessBeforeInitialization(result, beanName);
if (current == null) {
return result;
}
result = current;
}
return result;
}
//ImportAwareBeanPostProcessor里面的postProcessBeforeInitialization
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
if (bean instanceof ImportAware) {
ImportRegistry ir = this.beanFactory.getBean(IMPORT_REGISTRY_BEAN_NAME, ImportRegistry.class);
AnnotationMetadata importingClass = ir.getImportingClassFor(ClassUtils.getUserClass(bean).getName());
if (importingClass != null) {
((ImportAware) bean).setImportMetadata(importingClass);
}
}
return bean;
}
在调用该处理器时,会获取ImportRegistry,这个ImportRegistry实际上就是之前parser里面的ImportStack
ImportStack那么是在什么时候注册进spring容器里面的呢?
答案:在刚解析完所有配置的时候,spring就会手动注册进单例池,供ImportAwareBeanPostProcessor使用。
public void processConfigBeanDefinitions(BeanDefinitionRegistry registry){
...
// Register the ImportRegistry as a bean in order to support ImportAware @Configuration classes
if (sbr != null && !sbr.containsSingleton(IMPORT_REGISTRY_BEAN_NAME)) {
sbr.registerSingleton(IMPORT_REGISTRY_BEAN_NAME, parser.getImportRegistry());
}
...
}
ImportAwareBeanPostProcessor在容器中取得ImportRegistry时(即ImportStack),就可以获取ImportStack存储的map里面的值了。这个值就是导入ImportAware的类上的所有注解信息。
需要注意的地方1:多处引用导致不能获取到元信息
注意这里有一个坑:我们先查看getImportingClassFor是如何取的注解元信息。
public AnnotationMetadata getImportingClassFor(String importedClass) {
List<AnnotationMetadata> annotationMetadata = this.imports.get(importedClass);
return CollectionUtils.lastElement(annotationMetadata);
}
CollectionUtils.lastElement:取最后一个元素。
需要需注意的时,Spring是用MultiValueMap来存储被Import的配置类的。
private final MultiValueMap<String, AnnotationMetadata> imports = new LinkedMultiValueMap<>();
MultiValueMap是spring自己实现的一个特殊map,一个键可以对应多个值(其实就是用list来作为值,添加新值的时候就添加到list里面即可)。
回顾一下这个map的作用:用来存储被Import的类是被哪个配置类导入的。
举个例子:
@Configuration
@Import(Teacher.class)
public class ImportConfig {}
public class Teacher {}
这两个类在解析完存储到map时,会变成key:com.slc.imp.base.Teacher ,value: ImportConfig类上的所有注解信息
spring为什么要用MultiValueMap来存储imports呢?
这是因为可能会出现被import的类被多次引入。比如Teacher类,被ConfigB引入,此时,map里面的Teacher这一条对应的value就会再增加一个元注解。
即:key:com.slc.imp.base.Teacher ,value: ImportConfig类上的所有注解信息, ConfigB类上的所有注解信息,
然后,getImportingClassFor调用CollectionUtils.lastElement时,总是取得最后一个元素,这样就会造成前面引入这个注解类的元信息获取不到了。
- 比如定义
@EnableA1和@EnableA2,两个注解都@import(A.class), - A类实现了
ImportAware接口 @EnableA1和@EnableA2在不同的配置类上面引入。
此时@EnableA2晚于@@EnableA1被解析,那么A类的importMetadata,就是使用@EnableA2的配置类上面的注解元信息。
所以:建议使用ImportAware时,一个@EnableXXX对应一个ImportAware类
需要注意的地方2:为什么说ImportAware需要和@import搭配使用?
@Override
public Object postProcessBeforeInitialization(Object bean, String beanName) {
if (bean instanceof ImportAware) {
ImportRegistry ir = this.beanFactory.getBean(IMPORT_REGISTRY_BEAN_NAME, ImportRegistry.class);
AnnotationMetadata importingClass = ir.getImportingClassFor(ClassUtils.getUserClass(bean).getName());
if (importingClass != null) {
((ImportAware) bean).setImportMetadata(importingClass);
}
}
return bean;
}
在ImportAwareBeanPostProcessor的后置方法里面,只判断了当前类是否是ImportAware的子接口,并没有判断是否是@Import的相关逻辑。似乎只要这个Bean只要实现ImportAware就可以进行逻辑处理了。
如果不通过@Import引入Teacher,换成@Bean,引入Teacher,是不是也可以?
ImportStack是ImportRegistry的子接口,查看spring源码对ImportRegistry的解释:Registry of imported class,翻译过来就是:导入类注册表。看来ImportRegistry就是专门为@Import的解析做支持的,查看spring对importstack的使用,可以发现只有在解析@Import时会往importstack里面加数据。
用上面这个例子来看,加入通过@Bean来注入Teacher,那么此时自然不会走@Import的解析路线,importstack里面根本就没有对应的值,所以此时importingClass为空,根本就不调用Teacher的setImportMetadata。
做个总结:只有@Import导入的ImportAware实现类,会进行回调。
需要注意的地方3:ImportAware的AnnotationMetadata是什么?
导入ImportAware的类上面的所有注解的信息(封装成AnnotationMetadata)
@Enablexxx+@Import,那么就是使用@Enablexxx的类上面的 所有注解信息
通常情况下我们使用@Enablexxx,其实只是为了获取@Enablexxx的属性值,但实际上获取到的不仅仅是@Enablexxx的属性内容。还要其他注解的内容。
@Abc("1")
@Def("2")
@Configuation
@Enablexxx("3")
pubic Class A{
}
比如这种情况,AnnotationMetadata就包含@Abc、@Def、@Configuation、@Enablexxx("3")的所有注解信息。
所以在”需要注意的地方1“里面的例子,明确指定了@EnableA1和@EnableA2在不同的配置类上面引入。因为如果是同一个配置类上面引入的。那么AnnotationMetadata还是可以获取到两个注解的信息,似乎就没有发生覆盖问题。(实际上只是碰巧)
核心关注点:AnnotationMetadata不是只获取@EnableXXX,而是导入这个类的所有注解,只是后者的所有注解包含@Enablexxx而已