
一、环境介绍
使用VirtualBox安装Ubuntu虚拟机。在Ubuntu中安装Hadoop和Eclipse3.8编译器。下载安装JAVA环境,下载jdk并完成Hadoop的伪分布式环境配置。在Eclipse中导入编译程序所遇到的所有需要的JAR包。启动hadoop,网站中下载 hadoop-eclipse-plugin且解压并添加进Eclipss使在Eclipse中可以成功编译运行MapReduce程序。
二、导入jar包

需要导入的jar包有
三、数据来源及数据上传
在百度中收集各大诗人的英文简介,存放于文本中并命名为zjh.txt。在VirtualBox软件中安装增强功能,并使用其双向拖拉文件功能将需要进行词频统计的zjh.txt传至hadoop中的桌面。

四、数据上传结果查看
使用命令查看文件是否存在:

将zjh.txt上传至hdfs中,使用-ls命令查看:

五、数据处理过程的描述
打开Eclipse软件,点击Window -->Open Perspective --> Other:

选择Map/Reduce视图:
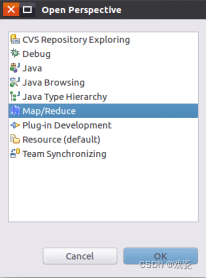
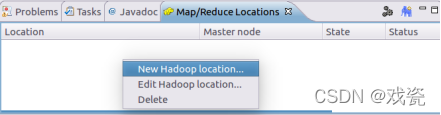
在生成的Map/Reduce视图中鼠标右键选择New Hadoop Location:
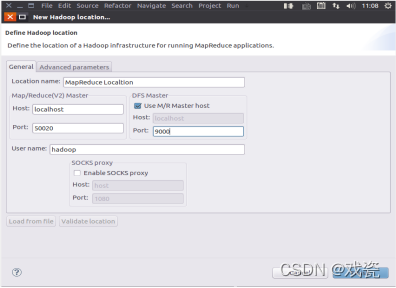
设置位置名称和设置主机的host port:9000:
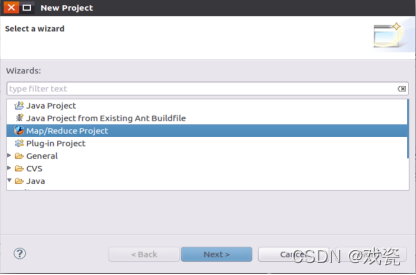
新建New Project --> Map/Reduce Project:
将project命名为WordCount:

项目生成完后再新建一个JAVA Class:

创建完类之后,将如下代码复制到WordCount.java文件中:
package org.apache.hadoop.examples;
import java.io.IOException;
import java.util.Iterator;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
public WordCount() {
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = (new GenericOptionsParser(conf, args)).getRemainingArgs();
if(otherArgs.length < 2) {
System.err.println("Usage: wordcount <in> [<in>...] <out>");
System.exit(2);
}
Job job = Job.getInstance(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(WordCount.TokenizerMapper.class);
job.setCombinerClass(WordCount.IntSumReducer.class);
job.setReducerClass(WordCount.IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
for(int i = 0; i < otherArgs.length - 1; ++i) {
FileInputFormat.addInputPath(job, new Path(otherArgs[i]));
}
FileOutputFormat.setOutputPath(job, new Path(otherArgs[otherArgs.length - 1]));
System.exit(job.waitForCompletion(true)?0:1);
}
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public IntSumReducer() {
}
public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {
int sum = 0;
IntWritable val;
for(Iterator i$ = values.iterator(); i$.hasNext(); sum += val.get()) {
val = (IntWritable)i$.next();
}
this.result.set(sum);
context.write(key, this.result);
}
}
public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private static final IntWritable one = new IntWritable(1);
private Text word = new Text();
public TokenizerMapper() {
}
public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()) {
this.word.set(itr.nextToken());
context.write(this.word, one);
}
}
}
}用命令行将/usr/local/hadoop/etc/hadoop 中将有修改过的配置文件复制到 WordCount 项目下的 src 文件夹中:
cp /usr/local/hadoop/etc/hadoop/core-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml ~/workspace/WordCount/src
cp /usr/local/hadoop/etc/hadoop/log4j.properties ~/workspace/WordCount/src
右键项目空白处,进入Run As -->Run Configuration :

在Arguments选项中进行设置。这里我是直接用zjh.txt当input文件输入,自定义了outputTest文件夹存放运行结果生成的文件。

设置完input、output参数后点击Run。可以看到运行成功的提示。

六、处理结果的下载及命令行展示
在hadoop中的hdfs中使用命令查看是否生成OutputTest:
$ ./bin/hdfs dfs -ls
使用-ls命令查看outputTest文件夹里存放的文件:
$ ./bin/hdfs dfs -ls outputTest
使用-cat命令打开outputTest/part-r-00000:
$ ./bin/hdfs dfs -cat outputTest/part-r-00000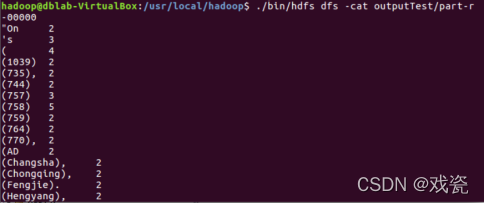
使用命令将outputTest文件夹下载到本地的outputTest文件夹中。
$ ./bin/hdfs dfs -get outputTest ./outputTest
查看/usr/local/hadoop是否存在outputTest文件夹,打开该文件夹
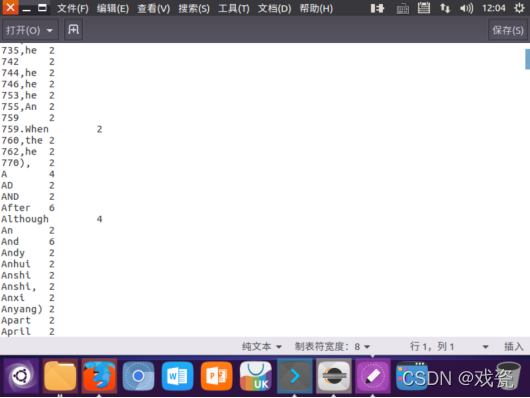
打开存放词频统计结果的part-r-00000
七、经验总结
在本次的hadoop的大作业中,使用eclipse对hadoop中的hdfs文件系统的文件进行词频统计,从最基本的安装hadoop,配置环境变量,安装软件或者插件一直到实现功能,每一个阶段都会遇到或多或少的困难,配置环境变量参数错误,命令中版本参数输入错误,我从各种各样的小问题中成长,不断提高对hadoop的掌握。本次的大作业的过程中,我发现我在完成过程中已经对实验的流程由那个懵懂无知的小白菜鸟到现在已经知道实验的步骤,从这么多次的实验走来,我连命令代码也开始变得熟悉。在WordCount的input、output目录中,曾遇到没有把文件上传至hdfs文件系统而不知道报的错误。
在本次的实验中也可以将i/output熟练掌握运用。最后学习了新的命令在hdfs中查看程序编译运行后的词频统计结果,还学习了将hdfs文件系统的文件或者文件夹下载到本地还有查看文件的命令。通过了老师的教导还有课后的实验,从一开始盲目遵循实验手册复制粘贴命令而不理解命令的用法和内容,到现在已经对hadoop的熟悉和热爱,在学习中也懂得了hadoop的功能和作用,在多领域中强大的运算功能为计算带来多大的便利。在课后我也会通过别的方式深入学习hadoop。
参考文献
[1].郭沫若.李白与杜甫.北京:中国长安出版社,2010.
[2].林子雨.大数据技术原理与应用.第2版.北京:人民邮电出版社,2017.
[3].Tom White.Hadoop权威指南.第4版.北京:清华大学出版社,2018.
[4].董西成.大数据技术体系详解:原理、架构与实践.北京:机械工业出版社.
[5].Hadoop in Action。Hadoop实战.北京:人民邮电出版社.