
文章目录
- 1、Abstract
- 2、Introduction
- 3、Contributions
- 4、Related work
- 4.1 GNN
- 4.2 Few-Shot Learning Methods
- 5、The Graph Few-Shot Learning
- 6、Framework
- 6.1 图自编码器 (c)
- 6.2 层次图表示门
- 6.2.1 Node Assignment
- 6.2.2 Representation Fusion
- 6.3 图结构原型
- 7、模型训练
- 8、模型测试
1、Abstract
- 对于具有挑战性的半监督节点分类问题,已经有了广泛的研究。
- GNN通过聚合邻居的信息来更新每个节点的表示;然而,大多数GNN层较浅,接收域有限,可能无法达到令人满意的性能,特别是当标记节点的数量相当少的时候。
- 为了解决这一挑战,我们创新性地提出了一种图小样本学习(GFL)算法,该算法融合了从辅助图中学习的先验知识,以提高目标图的分类精度。
- 辅助图与目标图之间共享一个以节点嵌入和特定于图的原型嵌入函数为特征的可转移度量空间,促进了结构知识的转移。
2、Introduction
- gnn通过汇聚(或消息传递)每个节点的特征,递归地更新每个节点的特征,从而捕获图拓扑和节点特征的模式。但是考虑到增加更多的层会增加训练的难度和节点特征的过度平滑,大多数现有的gnn具有浅层,接受域受到限制。因此,gnn不能很好地描述全局信息,当标记节点的数量特别少时,其工作效果也不理想。
- 受最近成功的几次学习的启发,我们从创新的角度出发,利用从辅助图(基类)中学到的知识来改进我们感兴趣的目标图中的半监督节点分类。背后的直觉在于辅助图和目标图可能共享局部拓扑结构以及类依赖的节点特征。例如,谷歌的现有社交网络同事群为预测亚马逊新出现的社交网络同事群的用户兴趣提供了有价值的线索。
- GFL的基本思想是学习一个可转移的度量空间,在这个空间中,节点的标签被预测为最接近该节点的原型的类别。度量空间实际上是用两个嵌入函数来表示的,嵌入一个节点和每个类的原型。
- 首先,GFL使用以gnn为骨干的图形自动编码器来学习每个节点的表示。其次,为了更好地捕获全局信息,我们建立了属于同一类的所有示例的关系结构,并将原型GNN应用到关系结构中来学习该类的原型。
- 最重要的是,将加密结构化知识的两个嵌入函数从辅助图(基类)转移到目标图(新类),以弥补标记节点的不足。除了两个节点级结构之外,注意我们还通过一个层次图表示门来制作图级别表示,以强制相似的图具有相似的度量空间。
3、Contributions
- 据我们所知,利用知识转移来改进图中的半监督节点分类是开创性工作。
- 我们提出了一种新的图小样本学习模型(GFL)来解决这个问题,它同时在图之间传输节点级和图级结构。
- 在四个节点分类任务上的综合实验验证了GFL算法的有效性。
4、Related work
4.1 GNN
GNN有两种方法,基于谱域和空域。谱方法主要在谱域学习图的表示,其中学习滤波器是基于拉普拉斯矩阵的。对于非谱方法,基本思想是开发一个聚合器来聚合局部特征集。其基本模型如下:

4.2 Few-Shot Learning Methods
- 基于梯度的小样本学习方法,旨在学习更好的初始化模型参数,可以在未来的任务中通过几个梯度步骤进行更新,或者直接使用元优化器来学习优化过程。
- 基于度量的小样本学习方法,提出从训练任务中学习广义度量和匹配函数。
我们提议的GFL属于第二类。这些传统的基于参数的小样本学习方法专注于独立和相同分布的数据,它们之间不存在明确的交互。
5、The Graph Few-Shot Learning
本文在概率分布𝜀中采样得到图序列
G
1
,
G
2
,
.
.
.
.
.
G
n
{G_1,G_2,.....G_n}
G1,G2,.....Gn。对其中的每一张图,划分为支持集
S
i
S_i
Si和查询集
Q
i
Q_i
Qi。
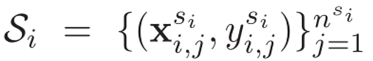
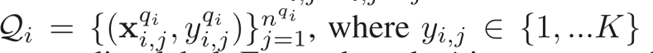
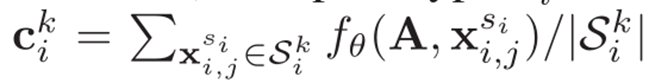
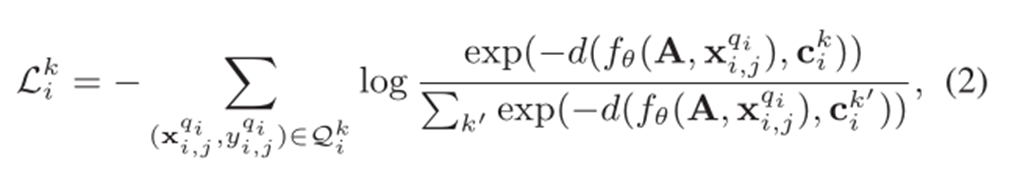
其中, c i k c_i^k cik为每个类图的原型表示, L i k L_i^k Lik为查询集上的损失。
- 查询集中节点标签的预测依赖于它的embedding与支持集中各类节点的原型 𝑐 𝑖 𝑘 𝑐_𝑖^𝑘 cik的度量关系d。embedding通过graph auto encoder学习得到.
- 图小样本学习的目标是从先前的图中学习一个具有良好广义的嵌入函数 Font metrics not found for font: .,并将其用于具有小支持集的新图。
- 为了实现这一目标,小样本学习通常包括两个步骤,即元训练和元测试。在元训练中,对θ的嵌入函数参数进行优化,使其在所有历史训练图上的预期经验损失最小。经过训练后,给定一个新的graph G t G_t Gt,学习的嵌入函数 f θ f_θ fθ可以在支持节点较少的情况下提高学习效果。
6、Framework
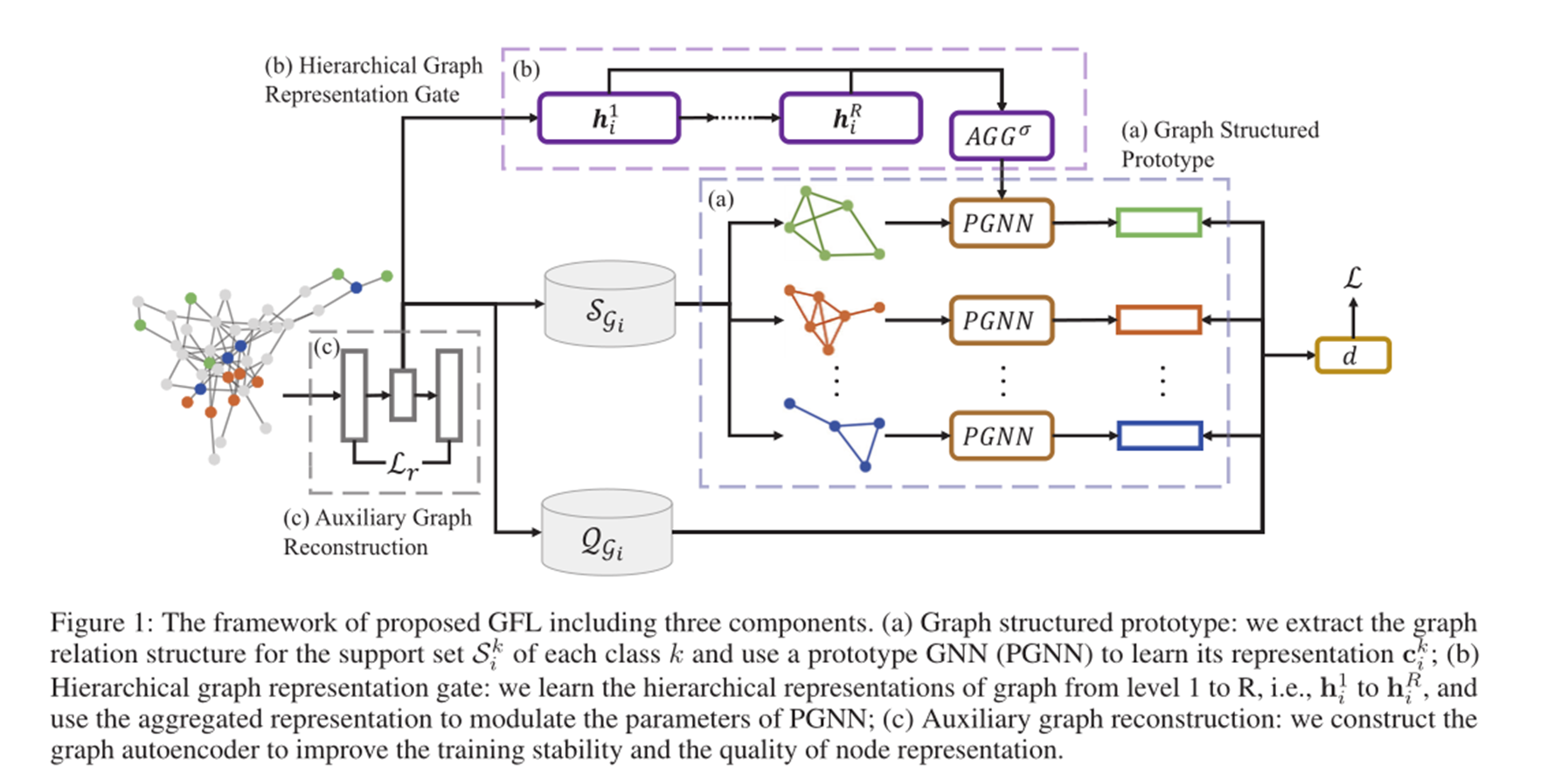
GFL的目标是利用节点级和图级的关系结构,将从现有图学习到的图结构知识适应到新的图
G
t
G_t
Gt。
- 在节点级,GFL捕获不同节点之间的关系结构;在(a)部分中,对于每一个类k,通过在 𝑆 𝑖 𝑘 𝑆_𝑖^𝑘 Sik中的样本构造相应的关系结构,并提出一个原型GNN (PGNN)来学习其原型表示。
- 对于图级结构,GFL学习整个图的表示,并确保相似的图具有相似的结构化知识。具体来说,如图(b)部分所示,PGNN的参数高度依赖于以分层方式表示的整个图结构。也就是说,PGNN的参数会使用(b)部分的最终输出。
- 最后通过查询集和类图原型表示相乘后,经过Softmax后进行预测,计算损失。
- 为了增强训练的稳定性和节点表示的质量,我们进一步引入辅助图重构结构,即©部分。
代码运行细节如下图所示:
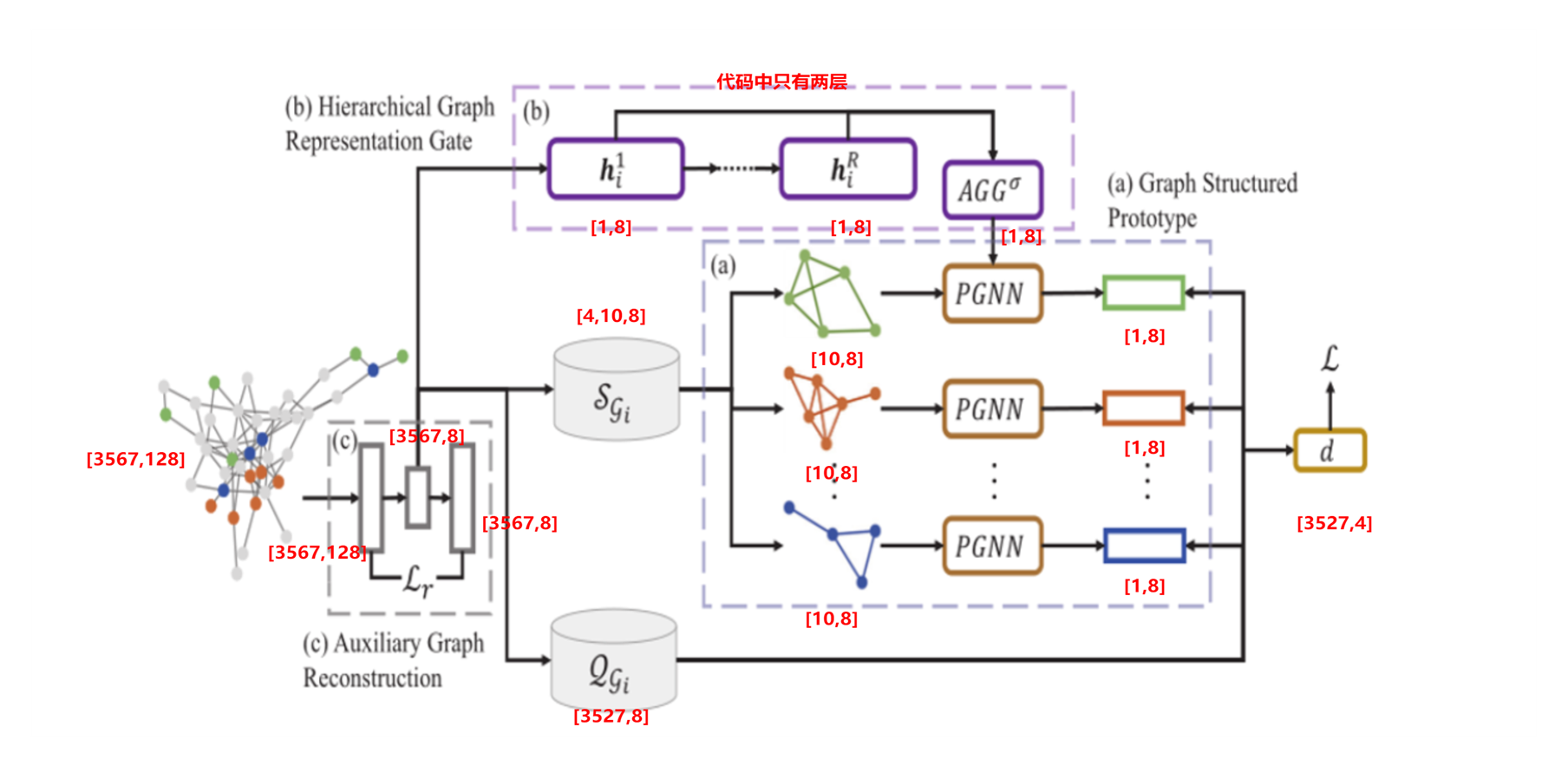
6.1 图自编码器 ©
- 作者提供了100个图(这100个图是从一个图采样而来),训练时从这100张图中随机选取batch个图,每个图是不一样的。为了观察方便,这里设置batch为1。
- 输入图有3567个节点,节点特征为128维。
- 首先经过图编码器,维度变成8维,然后再进行解码,维度也为8维。
- 然后计算重构损失。

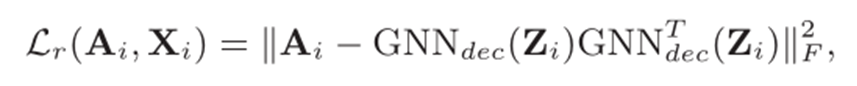
其中,
H
i
H_i
Hi为输入的图节点特征,
∣
∣
.
∣
∣
F
2
||.||_F^2
∣∣.∣∣F2为Frobenius 范数,计算方法是矩阵的各个元素平方后累加。
6.2 层次图表示门
这部分通过对整个图进行特征提取,然后将其提取的信息作为参数用于PGNN中,提供全局共享信息,因为单单使用节点级表示是不够的。
- 首先, h 𝑖 1 ℎ_𝑖^1 hi1为第一层,其值为图自编码器隐藏层的全局平均池化,变化过程为:[3567,8]–>[1,8]
- 然后进行图更新,代码中只计算了两层,即 h 𝑖 1 , h 𝑖 2 h_𝑖^1,ℎ_𝑖^2 hi1,hi2。然后对其进行contact,变为:[1,16],然后通过一个Linear层变为:[1,8]。
该模块详细细节如下:
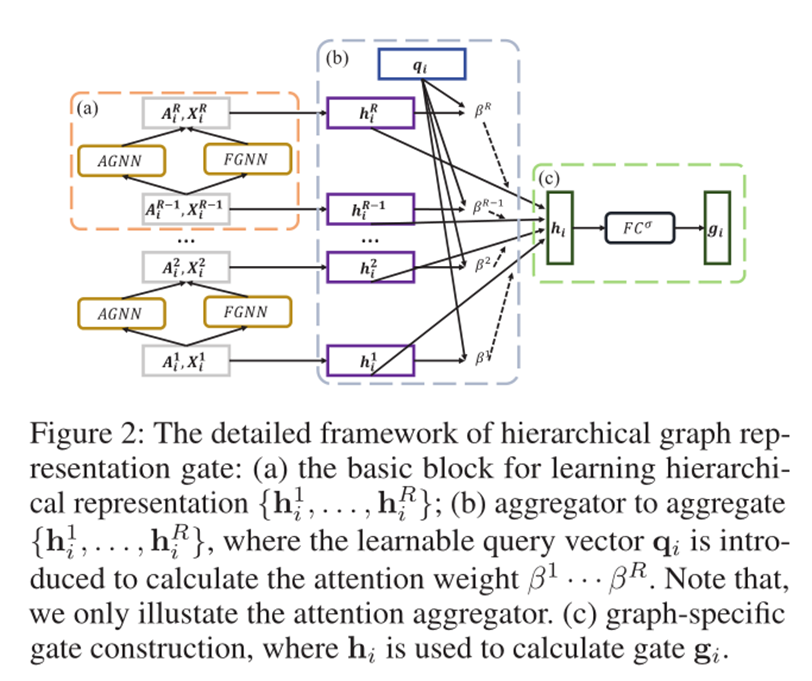
每个层次的层次图表示是通过节点分配和表示融合两个层次阶段的交替来完成的。
6.2.1 Node Assignment
在一个图
G
i
G_i
Gi的 r 层中,
K
r
K^r
Kr表示节点的数量,
A
i
r
A_i^r
Air表示邻接矩阵,
X
i
r
X_i^r
Xir表示特征矩阵。
Node Assignment 用
P
i
r
−
>
r
+
1
ϵ
R
K
r
∗
K
r
+
1
P_i^{r->r+1}\epsilon R^{K^r * K^{r+1}}
Pir−>r+1ϵRKr∗Kr+1表示,其计算方式如下:
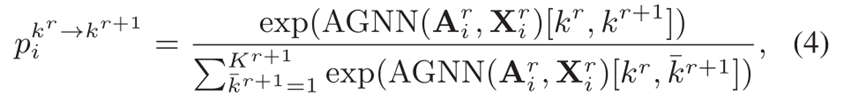
整个分配矩阵包括每个分配概率 p i k r − > k r + 1 p_i^{k^r -> k^r+1} pikr−>kr+1,记为:

Node Assignment后节点数量不变,变化的是节点的特征。
6.2.2 Representation Fusion
下一层的
A
i
,
X
i
A_i,X_i
Ai,Xi计算方式如下:
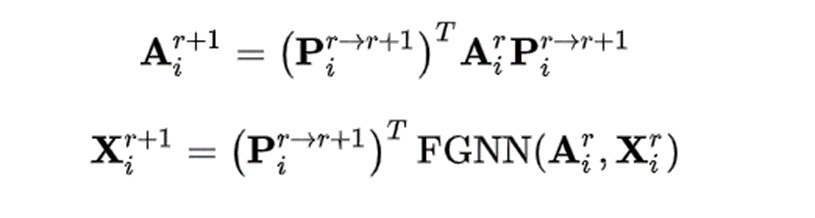
每一层的
h
i
h_i
hi为当前层的
X
i
X_i
Xi的平均池化:
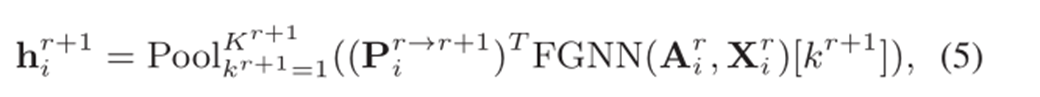
经过不断的提升图的level,我们得到了一个不同层次的图特征表达集合{𝒉_𝒊^(𝟏 ),𝒉_𝒊𝟐,𝒉_𝒊𝟑…𝒉_𝒊^𝑹}。为了进一步聚合集合,作者提出了两种聚合方式:mean pooling aggregator和attention aggregator :
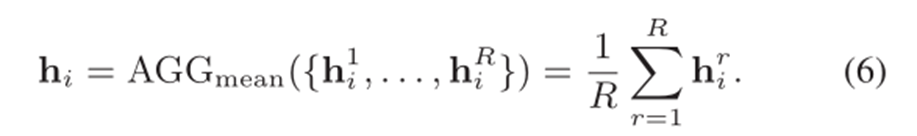
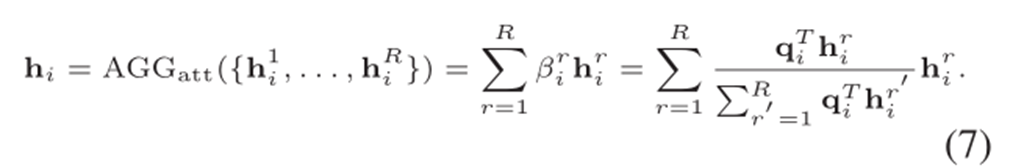
再进一步,需要将该特定图
h
i
h_i
hi融合到PGNN中的参数∅中。在理论层面,作者通过门控+点乘的方式去激活∅的不同维度,在实践层面,更像是为了使
h
i
h_i
hi和∅维度保持一致。具体体现在:
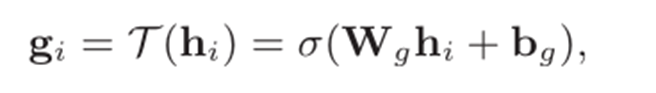

具体代码实现流程如下:
- 之前层次图表示门最后得到:[1,8]的数据,记为P。
- 将P送入Linear(8,64),然后得到[1,64],再进行view(8,8),得到:[8,8],记为gate_weight。
- PGNN的参数为:[8,8],记为weight
- 然后将两个参数对位相乘, gate_weight ° weight 作为PGNN的新参数。 ° 为对位相乘。
6.3 图结构原型
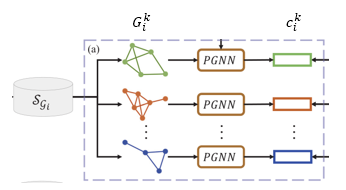
-
𝐺 𝑖 𝑘 𝐺_𝑖^𝑘 Gik: 类别k的所有样本构造的图,其邻接矩阵为 𝑅 𝑖 𝑘 𝑅_𝑖^𝑘 Rik,邻接矩阵的构建依赖于相似性度量方法,如如k-hop公共邻居的数量,节点间拓扑距离的逆。
-
该类节点的特征为经过graph autoencoder的 f θ ( S i k ) f_\theta (S_i^k) fθ(Sik)
-
为了提高邻接矩阵的鲁棒性并减少离群点的干扰,对相似性低于某个阈值(u)的两个点在邻接矩阵中赋予固定的值。 w = u 0 ( u 0 < u ) w = u_0 (u_0 < u) w=u0(u0<u)
-
所以,graph structured prototype构建方式为:
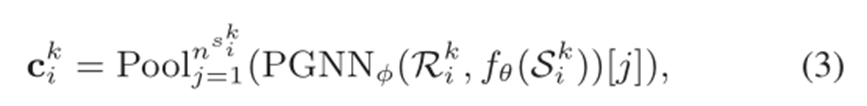
流程如下:
- 此部分数据是从输入图的每个类别中分别随机采样10个节点,最终形成4个类别的图,每个图10个节点,因此是4-ways 10-shots任务。
- 其余的3527个节点用于对模型进行评估。
- 每个类别图的邻接矩阵的构建依赖于相似性度量方法,如k-hop公共邻居的数量,节点间拓扑距离的逆等等。
- 在PGNN中,层级门控制模块的参数会加入PGNN中,增加全局信息。
- 经过PGNN后,每个图的维度变为:[10,8],然后进行平均池化,得到:[1,8].
7、模型训练
损失函数如下: L i L_i Li为查询集的交叉熵损失, L r L_r Lr为图自编码器的重构损失。
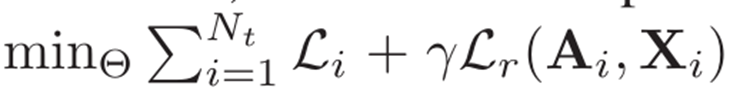
8、模型测试
- 模型训练好后,进行新图的预测。
- 读取一个新图,其中支持集的40个数据是有标签的,相当于小样本数据,其余的数据不给标签,是需要进行预测的。
- 通过这40个数据得到这个新图的类结构原型,使用之前训练好的模型参数,然后进行预测,来评估此模型的性能。
- 之前训练好的模型参数作为先验知识来指导新数据的预测。