
那么插入的第一条记录的变长字段列表为[04,02,01],分别对应dddd,bb,a的长度(逆序排可变长度列)
其长度有如下两条规则
-
若列的长度小于255( 2 8 2^8 28),占用一个字节表示(一个字节刚好8位)。
-
如果超过255,那就占用两个字节表示,2个字节就是16位,也就是65536,varchar最大长度就是16位,超过了就会变成Text类型。
NULL标志位
该位指示了该行数据中是否有NULL值,有则使用1来表示,该部分占的字节大小大概为1字节,比如当NULL标志位为06时,06转换为二进制为110,表示第二列和第三列为NULL(如果超过了8列会怎么办?)。
记录头信息
记录头信息固定占5字节(40位)
详细如下
| 名称 | 大小(位) | 描述 |
| — | — | — |
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否被删除 |
| min_rec_flag | 1 | 如果该记录是预先被定义为最小的记录,值为1 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的排序记录 |
| record_type | 3 | 记录该行记录的类型,000表示普通,001表示B+树的结点指针。。。 |
| next_record | 16 | 页中下一条行记录的相对未知 |
| Total | 40 | |
记录头信息(Record Header)的最后两个字节就是next_record,next_record代表下一个记录的偏移量,即当前记录的位置加上next_record的偏移量就是下一条行记录的起时位置,所以在页的内部,实则上也是通过一种链表的形式来串连各条行记录的
存储列的部分
最后的部分就是实际存储每个列的数据,这里需要注意的是,NULL不占该部分的任何空间,NULL除了占有NULL标志位的1字节空间外,实际储存是不占有任何空间的。
另外一点要注意的是,每行数据除了拥有用户定义的列外,其实还会有两个隐藏列,为事务ID列和回滚指针列,分别为6字节和7字节的大小,同时,若InnoDB表没有设置主键,需要使用到rowid,还会有一个6字节的rowid列
实战看一下里面Compact记录
这是b表的数据
其中a 、c、e都是varchar型,而d、f是Int型
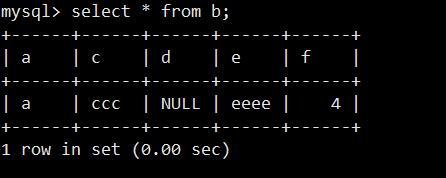
现在来查看一下b.ib里面的情况
hexdump -C bibd //linux命令
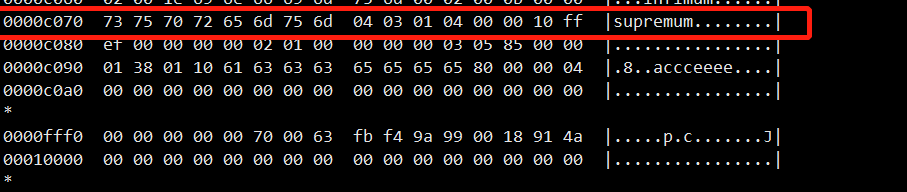
红色框住的一部分就是表中第一行的数据
可以看到04 03 01对应的就是eeee,ccc,a的长度(也是反序)
然后04就是NULL标志位,04转换成二进制就是0010,即第一第二列不为空,第三列为空,第四列不为空,正好也是对应行的数据
Redundant行记录
这种行记录是为了兼容5.0版本之前而存在的,采用了以下格式进行储存
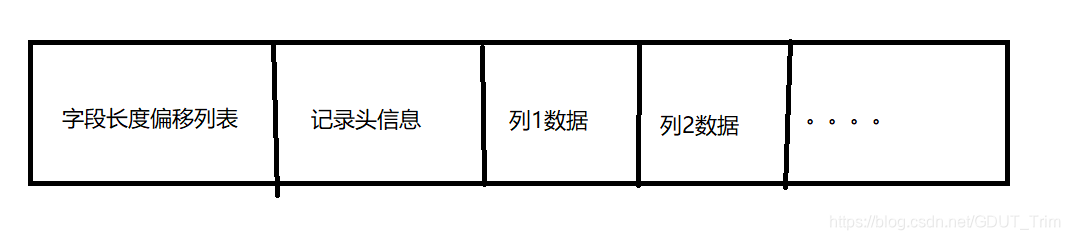
Redundant行记录与Compact行记录最大的区别就是少了字段长度偏移列表,其他都是比较类似的。
字段长度偏移列表
Redundant行记录第一个部分是字段长度偏移列表,但与Compact行记录不一样(Compact是变长字段长度偏移列表),同样是按照列的顺序进行逆序放置的,同样拥有下面两条规则,
-
若列的长度小于255(字符),占用1个字节表示
-
若大于255,占用2个字节表示
-
与Compact不同,Redundant存储的是所有列的长度,包含NULL列,NULL列如果是可变长度类型的话,记录为0,如果不是可变长度会有长度。
| 名称 | 大小 | 描述 |
| — | — | — |
| () | 1 | 未知 |
| () | 1 | 未知 |
| deleted_flag | 1 | 该行是否以被删除 |
| min_rec_flag | 1 | 该记录是预先被定义为最小的记录时,该字段为1 |
| n_owned | 4 | 该记录拥有的记录数 |
| heap_no | 13 | 索引堆中该条记录的索引号 |
| n_fields | 10 | 该行记录中列的数量(与Compact不同) |
| 1byte_offs_flag | 1 | 偏移列表为1字节还是2字节(与Compact不同) |
| next_record | 16 | 页中下一条行记录的相对位置 |
| Total | 48 | |
存储列的部分
存储列的部分与Compact格式基本一样,同样隐藏了2个列(事务ID列和回滚指针列),除了对NULL值的处理。
对NULL值的处理
Redundant对NULL值的处理可能会占用空间的,在前面的字段长度偏移字段里面是有记录NULL值长度大小的,如果为可变类型才为0,且该NULL值在存储列部分不占空间,但有些比如char类型,为NULL的话,在字段长度偏移字段是有长度大小的(不为0,具体根据建表时定义的长度计算),对于该NULL值,在存储列部分是占空间的。
行溢出数据
InnoDB存储引擎可以将一条记录中的某些数据存储在真正的数据页面之外,一般是针对于BLOB、TEXT这些大类型,行溢出是指字节溢出,而不是字符长度溢出,不过其实BLOB并不一定将数据放出行溢出,而且VARCHAR类型即使没有溢出也依然有可能被存放在行溢出数据。
MySQL的VARCHAR类型可以存放 2 16 2^{16} 216字节,即65535字节,如果超过这个字节或者等于这个字节会变成TEXT类型(要改变SQL_MODE),比如下面的建表语句,但其实使用65532会报错的,因为字段本身还会有其他开销,所以只可以存65532字节
//注意这里一定要使用latin1的字符集,因为在这个字符集内,一个字符的最大占用字节为1
//所以varchar(65535)才会对应字节长度为65535,
//如果使用utf8的话,一个字符的最大占用字节为3,总最大的字节长度就是65535*3
CREATE TABLE i(
a VARCHAR(65535)
)ENGINE=INNODB,CHARSET=latin1;
此外要注意的是,这个65535字节,并不是指单个varchar,而是指整个表非大字段类型的字段的bytes总和
但是问题来了?InnoDB存储引擎的页为16KB,也就是16384字节,是怎么存储65535字节的呢?
其实,在一般情况下,InnoDB存储引擎的数据都是存放在页的B-tree node中的(也就是索引的叶结点),但是如果发生行溢出的时候,就会存放在页类型为Uncompress BLOB页(未压缩的二进制页),而叶子结点里面对于该列只会存储前768字节数据,后面是偏移量,该偏移量是指向行溢出页的,其余的都在Uncompress BLOB页中。
总体来说的结构会如下所示
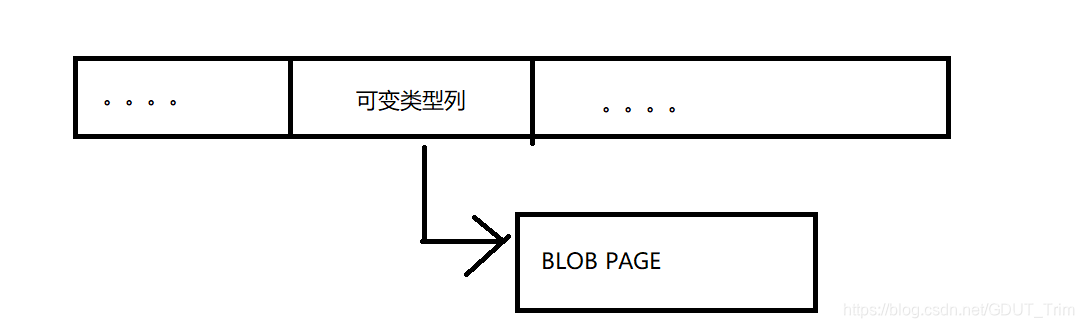
下面就来详细说一下什么时候会发生行溢出
首先,我们要认识InnoDB存储引擎表是索引组织,即是一棵B+树,而B+树最低标准是基于2-3结点创造的,即每个结点都必须要有至少2个数据(对于InnoDB来说,子结点就是页,里面的数据就是行,所以每页里面都至少有2行)否则不可能形成树结构,而会形成链表,所以,InnoDB发生行溢出数据的条件,就是叶子结点无法存储至少2行数据。
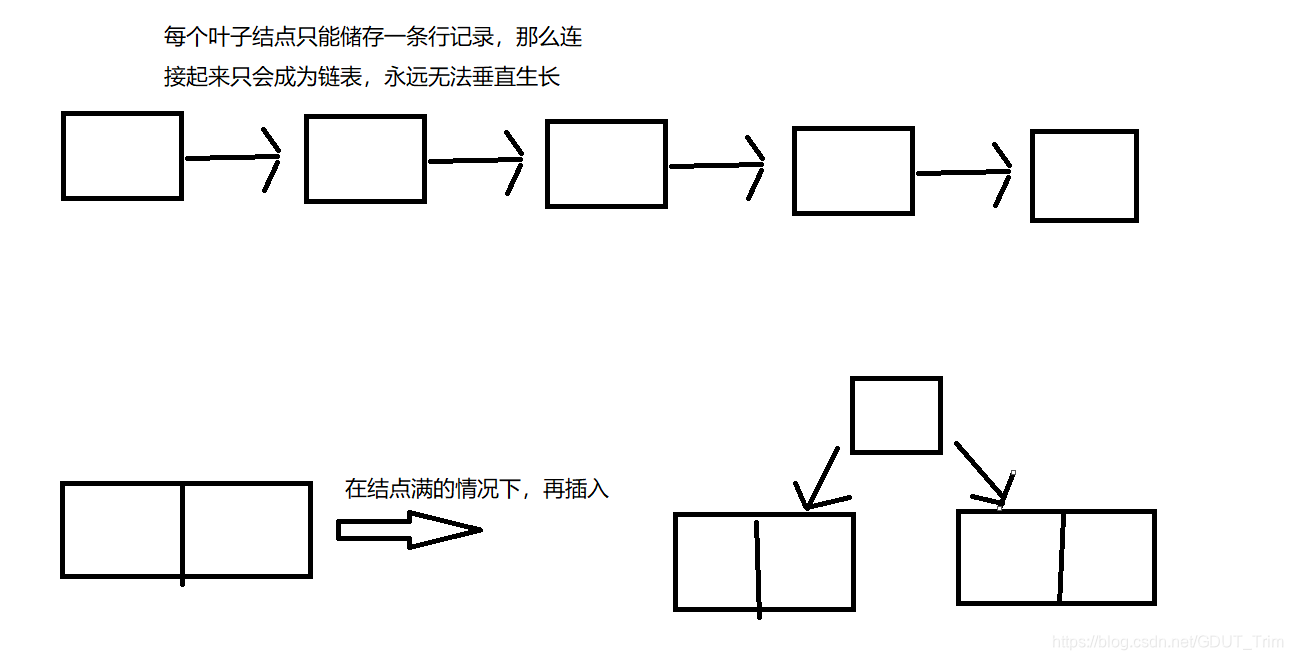
即并不是只要varchar或者text等类型,超过了768字节就会发生行溢出,只是如果发生了行溢出,那么varchar和text等类型,只会保留768字节,剩余的部分会放到BLOB PAGE里面。而发生行一处的条件就是一个页里面,存放不下两条行记录(书上说的是每一行的列的总字节长度为阈值为8098字节,即varchar(8098)【跟16KB的一半差不多】,即超过了这个字节,那么该页存储了这行就无法存储第二行,也就要发生行溢出)。所以,即使是BLOB和TEXT类型,也是要判断该页是否可以存放两行记录。
那可不可能是其他类型的列发生行溢出呢?比如Int、BIGINT
这是不可能的,因为InnoDB对单表有列数的限定,最多只有1024个列,而类型里面占空间最大的为8位,即使1024个列都是最大位数,都不会超过(所以发生行数据溢出的,肯定是有变长类型或者TEXT和BLOB类型,虽然这里1024*8是大于8098的,是因为8098没有加上偏移量【指向溢出页的】)。
Compressed和Dynamic行记录模式
从MySQL5.7开始,默认的行记录格式为Dynamic格式,Compressed和Dynamic行记录格式称为Barracuda,而以前支持的Compact和Redundant称为Antelope文件格式。
这两种记录格式,如果发生了行溢出情况,对于存放在VARCHAR、VARBINARY、BLOB、TEXT中的数据采用了完全的行溢出的方式(即该行记录中最长的一列),在该行记录的存储列的部分,对于BLOB类型的,只会存放20个字节的指针,实际的数据都会在溢出页中,这里的溢出页称为Off Page,而之前的Compact和Redundant这两种格式会存放768个前缀字节。
唯一的不同是Compressed的行记录格式的另一个功能就是,存储在溢出页其中的行数据会进行压缩,使用zlib算法,因此对于BLOB、TEXT、VARCHAR这类大长度类型的数据能够进行非常有效的存储。不过这个是牺牲CPU来获取存储空间的,因为执行算法需要使用CPU
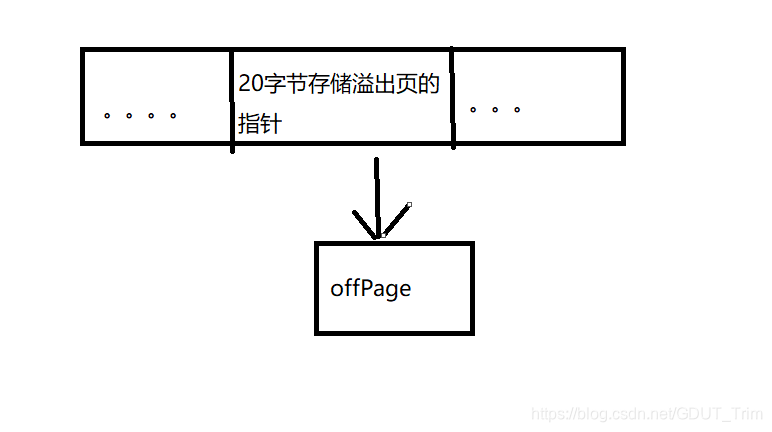
Dynamic、Compressed记录行的格式
Dynamic记录行的格式其实是跟Compact是一致的,除了使用了完全行溢出外,其他属性基本没变。
CREATE DATABASE hehe;
USE hehe;
CREATE TABLE a(
a VARCHAR(4),
b VARCHAR(5),
c
【一线大厂Java面试题解析+后端开发学习笔记+最新架构讲解视频+实战项目源码讲义】
开源分享完整内容戳这里
INT,
d VARCHAR(6),
e INT
)ENGINE=INNODB,CHARSET=utf8;
INSERT INTO a SELECT “aaa”,“bb”,NULL,“c”,4;
这是表的状态

同样,查看它的输出