
网上爬取的数据如何制作成表
- 一、背景
- 二、操作办法
- 三、总代码
一、背景
从网上搞到一份数据,如图所示:

我该怎么制作成excel表呢?最后结果为:
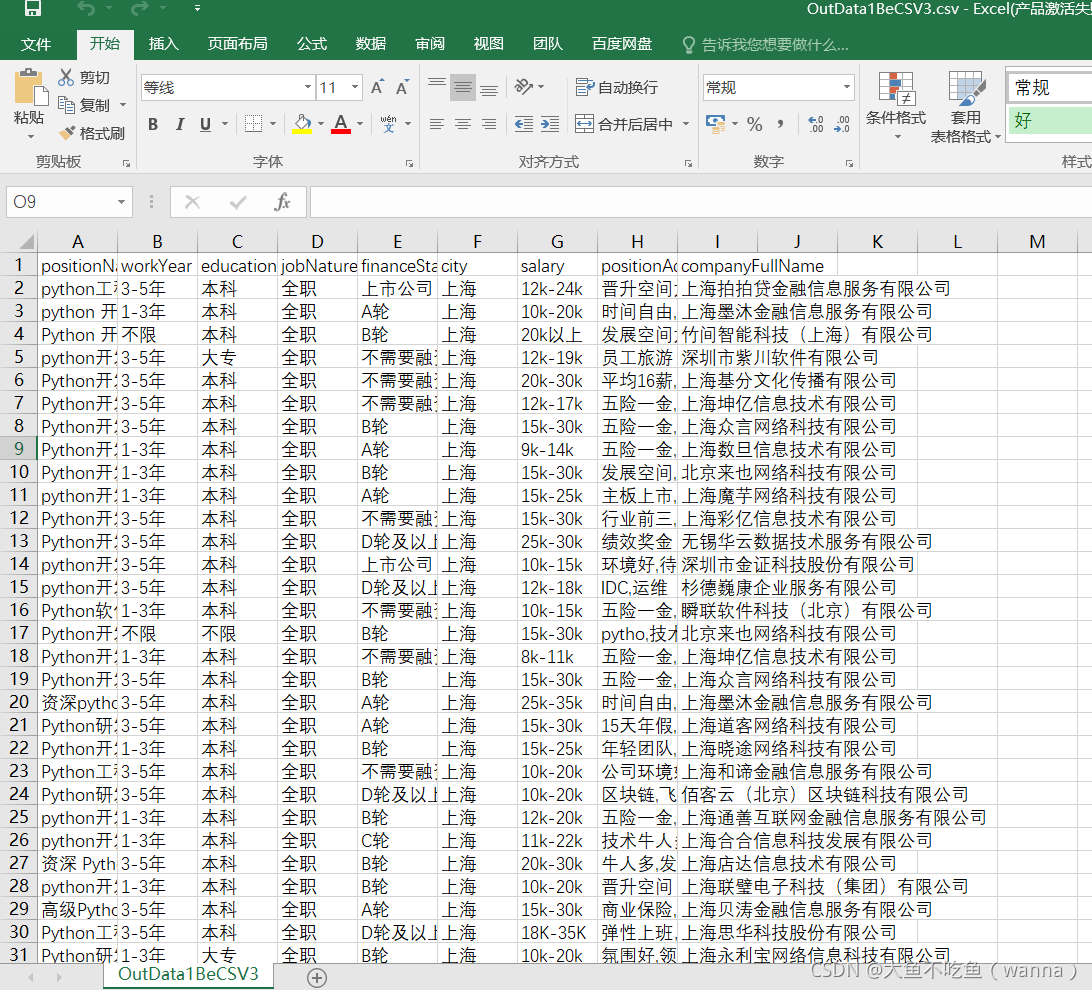
二、操作办法
1、由于最后要生成表格,这里使用csv模块,不知道有没有 xlxs的响应模块,我也没用过。这个csv模块是python自带的包,无需自己下载。
import csv
2、发现爬取的文件是一个字典列表,我们尝试分析里面的字段,不妨给它加上一个表头:
headers = ['positionName', 'workYear', 'education', 'jobNature', 'financeStage',
'city','salary','positionAdvantage','companyFullName']
3、开始操作文件:
with open(r"toBeCSV\data1.txt","rb") as f:
#rows1 = eval(f.read().decode("gbk")) #将bytes转换为str,用decode;反之用encode
rows1 = eval(f.read().decode("gbk")) #从磁盘上读取的就是字节流,即Bytes
#print(rows1)
4、关于decode和encode,实际上用的时候我还是分不太清楚,这里用decode没毛病,我试试用encode,encoding:
AttributeError: ‘bytes’ object has no attribute 'encode’
AttributeError: ‘bytes’ object has no attribute 'encoding’
- 说是没有这个属性。其实Open里面也可以使用encoding,如:
python with open(r"toBeCSV\data1.txt","r",encoding='gbk') as f:这里使用utf-8,报错:
UnicodeDecodeError: ‘utf-8’ codec can’t decode byte 0xb9 in position 25: invalid start byte
查看了一下,原来是我使用了’rb’,以二进制的形式读取文件内容,所以后面要用decode解码。
然后我把’rb’改为了’r’,发现没有报错,生成的文件内容也不是乱码,看来是我多此一举了。

5、至于为什么使用with open as,请移步这篇博客(我也是刚刚百度的):
大致的意思说,由于安全性,很可能造成操作系统读取文件执行过程出现意外,使程序终止,而无法及时关闭文件,导致内存告急(os可打开的文件数量是有限的)。固然可以使用try——finally方法,但是不如with open ……as来的简洁。
https://blog.csdn.net/xrinosvip/article/details/82019844
6、关于eval() 函数,它用来执行一个字符串表达式,并返回表达式的值。
这里不用报错:AttributeError: ‘str’ object has no attribute ‘keys’。
对比一下输出:
7、将表头写入新的文件:
#发现写入的csv文件中是写一行空一行。解决办法是,在open()参数中将newline设置为空
with open(r"toBeCSV\OutData1BeCSV3.csv",'w',newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader() #写入表头
f_csv只是一个变量,跟那个文件操作指针f不是一个东西呀,也相关不大。
8、把剩下的内容写入文件:
f_csv.writerows(rows1)
三、总代码
我一开始依偎要用pandas,后来发现只需要导入csv模块即可,而这个模块是python自带的包,无需自己下载。
def usePandasFromTxtToBeCSV():
import csv
headers = ['positionName', 'workYear', 'education', 'jobNature', 'financeStage',
'city','salary','positionAdvantage','companyFullName']
#{"positionName": "python工程师", "workYear": "3-5年", "education": "本科", "jobNature": "全职", "financeStage": "上市公司", "city": "上海", "salary": "12k-24k", "positionAdvantage": "晋升空间大、福利好", "companyFullName": "上海拍拍贷金融信息服务有限公司"}
with open(r"toBeCSV\data1.txt","rb") as f:
#rows1 = eval(f.read().decode("gbk")) #将bytes转换为str,用decode;反之用encode
rows1 = eval(f.read().decode("gbk")) #从磁盘上读取的就是字节流,即Bytes
#print(rows1)
# 可以将字典型列表转化为表格模式
#发现写入的csv文件中是写一行空一行。解决办法是,在open()参数中将newline设置为空
with open(r"toBeCSV\OutData1BeCSV3.csv",'w',newline='') as f:
f_csv = csv.DictWriter(f, headers)
f_csv.writeheader() #写入表头
f_csv.writerows(rows1)
usePandasFromTxtToBeCSV()