
前言
对遗留系统的微服务化改造,从整体上来说,整个过程包含两个部分:一,通过某一种方法论将系统进行微服务划分,比如DDD倡导的限界上下文划分方法。根据系统的特点和运行状态,又分为具体的两种实施策略,绞杀者模式和修缮模式。二,数据库的拆分,只有在数据层面也拆分开,才能真正达到服务化的目的。具体也可以分为,与业务服务拆分同时进行,或者等业务服务拆分后再单独进行两种策略。
似曾相识的步骤
如果不考虑在拆库的同时引入新功能,拆库其实也是一种重构。Martin Fowler在**《Refacotring》中强调数据库具有高度的耦合性,数据库重构存在相当的难度。不过好在还有另一本权威著作来为此背书,那就是《Refactoring Databases》**。
来看看这本书提到的数据库重构步骤:
- Verify that a database refactoring is appropriate
- Choose the most appropriate database refactoring
- Deprecate the original database schema
- Test before, during, and after
- Modify the database schema
- Migrate the source data
- Refactor external access program(s)
- Run your regression tests
- Version control your work
- Announce the refactoring
- What you have learned
是不是和代码的重构似曾相识,分析->测试->修改->测试……
同时也看看我们的数据库拆分实践是否能和这些步骤有所呼应。
背景介绍
我们曾经对某客户企业的系统做服务化改造。根据其组织架构和系统特点,最终采取了先服务拆分,再数据库拆分的演进路线。
到服务化改造基本完成时,系统逻辑结构如下图所示:
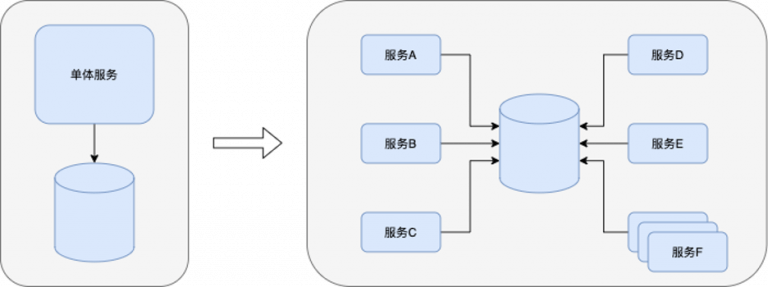
右边的图完全就是《Refactoring Databases》里说的Multi-Application Database。
接下来就是数据库的重构了,也是本文的重点。
分析在前
系统数据库采用MySQL,由于之前是一个大单体,所有的数据都存在一个数据库里。随着业务的增长,单库虽然已经使用了顶级的硬件,性能仍显不足。所以不管从架构上,还是性能上,拆库都迫在眉睫。这也就回答了Verify that a database refactoring is appropriate的问题。
数据库重构相对于代码重构毕竟影响更广,风险更大。直接采用XP的模式风险太大,必要的分析必不可少,整个过程力求一次正确。
首先必须了解数据库的全貌,经过一番沟通梳理出架构图如下:
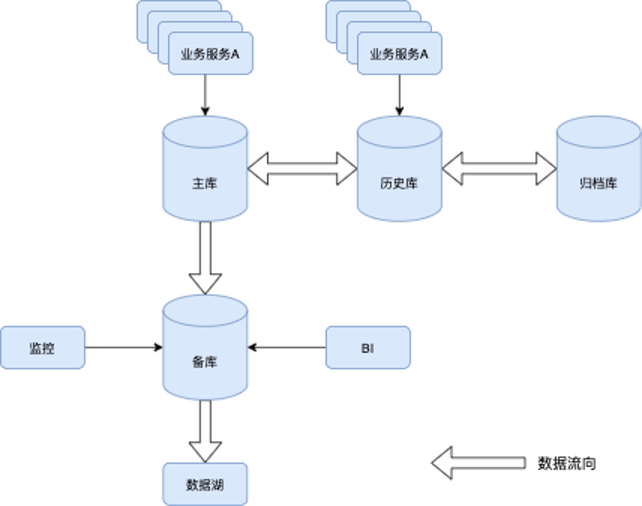
整个数据库由主库,备库,历史库,归档库组成,备库主要用于监控和BI等,历史库用于存放达到某个状态后的订单数据,主库和归档库由于历史原因都会被业务服务访问。归档库性能相对较差,只用于归档数据。
主库,历史库,归档库之间可以互相迁移数据,迁移代码是完全自研的,支持单个订单的一系列数据迁移,也支持批量的订单迁移。
业务服务的迁移历经一年多的时间,单体也进化成了十几个微服务,要想一次性把数据库全部拆开不太现实,风险也不可控。最好的方式是找出当前数据库的瓶颈,先将业务上访问量最大的部分拆开。经过调研,决定先将数据库一分为二,先将发货单拆出去,类似于修缮模式,订单及其他数据先保留。这也呼应了Choose the most apporiate database refactoring,所以设想拆分后的数据库应该如下图所示:
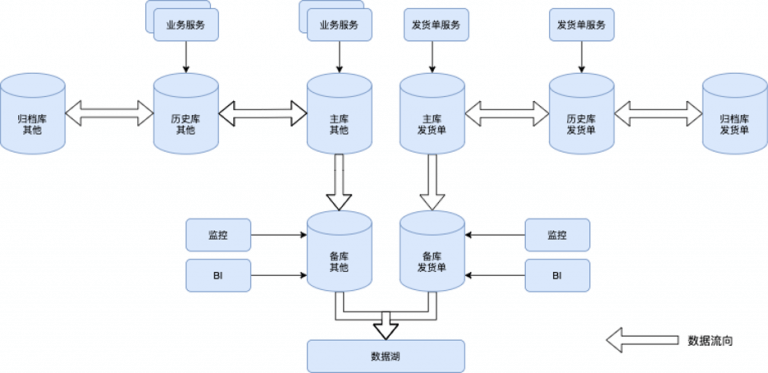
从图上不难看出,需要修改的点包括:
1. 业务代码
1.1 发货单服务的数据库配置
1.2 所有类似join查询的级联操作,主要集中在页面查询,导出,报表等。(写入操作在微服务拆分时基本已经修改)
2. 数据
2.1 新建发货单数据库,schema和用户
2.2 已有的发货单相关的数据迁移至新数据库
3. 迁移代码
3.1 源库和目标库都要支持多源配置,现在是一分二,将来会更多
3.2 迁移逻辑,要保证数据一致性。即一个订单的数据要么全在主库,要么全在历史库或归档库
4. 监控和BI
4.1 多源配置
4.2 监控逻辑修改
中间过程
通知上下游
这一点非常重要,在一个涉及多部门的系统上做数据库迁移。有些影响绝不是靠自己就能考虑周全的,在做所有迁移之前就要通知各方评估各自的影响和改动周期。
业务代码的修改
- 测试先行
重构最重要的一点是不改变程序的外在表现。对于数据库重构来说,只需要保证对外暴露的API在特定输入下,输出是一致的。
在这个点上,测试是比较容易写的。自动化测试和人工测试同时展开,以黑盒集成测试为主。在每个API修改之前先根据现有结果编写测试,同时QA记录输入,输出,注意各种边界情况的测试。在这个阶段基本忽略现有代码逻辑的正确性,先保证拆库前后API的行为一致。
当然,这是理想的情况,在真正开始做以后,就会发现情况并不是这么简单。
- 业务代码修改
指导思想是将级联查询修改为API调用补齐数据。然而这里面有一个特殊情况,当遇到join,groupBy,有where条件,再加上分页的场景,API调用补齐数据的方式就不能很好的处理。
说说当时的几种处理办法:
- 非批量的查询,通过API补齐数据。
- 批量查询,但是级联的数据不在过滤条件中,通过API补齐数据。根据性能和调用频率考虑加缓存。
- 批量查询,级联数据在过滤条件中,没有分页(隐含的意思是数据量小),通过API先拿到数据,在内存中处理。
- 批量查询,有过滤,有分页。跟业务沟通是否能在查询结果中删除级联的数据,如果不行,是否能在过滤条件中删除级联的数据。
实际操作下来,发现其实业务上并没有设想的那么难。首先只有个别API存在这种情况,其次这些API的一些字段可能是一些历史原因造成的,删除对现有的业务影响并不大。
当然如果最终无法在业务上达成一致,那就要考虑在报表库和数据湖层面做聚合了,方法总是有的。
数据迁移
- 开发过程
过程中有三种方法:
- 同一个物理库,保持相同的schema,不同的用户通过授权不同的表,达到逻辑划分的目的。例如为发货单服务新建一个数据库用户,只把发货单相关的表授权给它访问。当前用户收回访问发货单表的权限。
优点:简单易操作,开发过程无需做数据迁移。
缺点:逻辑划分毕竟不能完全模拟真实的生产环境。例如有些表是多个服务共享的,开发时只能多个用户同时授权。如果业务代码修改不彻底,就会出现一个服务写入,其他服务读取的情况。一旦上了生产,表做了物理隔离,就会造成读取不到数据的事故。
grant select,insert,update,delete on existing_schema.existing_table to 'new_user'@'%';
- 同一个物理库,不同的schema,可以保持相同的用户,这样修改较少。
优点:几乎可以模拟生产数据库,业务代码好排查,毕竟新加的schema在之前的业务代码里没有,很容易测试发现问题。
缺点:需要将部分表迁移至新schema。如果是MySQL,在不同schema之间迁移表还是比较容易的。例如:
alter table existing_schema.existing_table rename new_schema.existing_table;
- 不同的物理库,schema是否修改取决于当前名称是否表意。
优点:完全模拟生产数据库
缺点:不同物理库之间要做数据迁移
回头看,有条件的情况下第三种方法最为保险。第二种方法性价比最高。
- 生产数据迁移过程
由于是线上运行系统,版本上线窗口时间有限,不可能在上线当晚执行全部的数据迁移,所以必须提前做,这样数据质量也有保证。
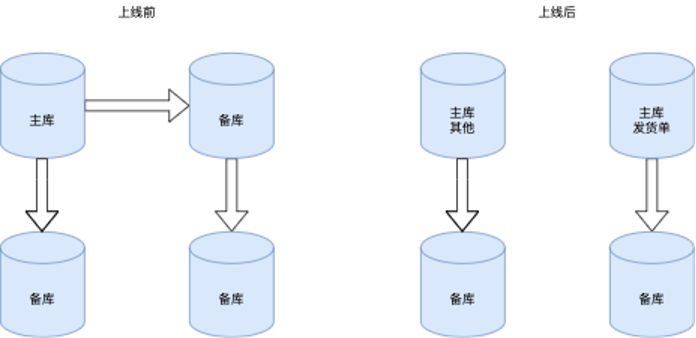
这里也有两种方法来做主备迁移:
- 利用MySQL的主从机制来同步,需要注意的是,在发货单主库(上线之前是主库的从库之一)需要打开
--log-slave-updates,否则无法再接一个从库。 - 利用第三方数据库同步工具,这类工具常常会带有UI,相对比较友好。
这样在上线前就可以不断检查数据迁移的质量,上线当晚只需要很短时间的停机,甚至不停机。上线后两个主库都包含了很多彼此的历史数据,可以不急于删除,以防需要回滚。
主备库的迁移代码修改
之前要迁移的表都在一个数据库里,迁移可以用一个事务来保证同时成功或失败。现在分布在两个库里,只能通过最终一致性来保证。
像以往的AP系统的处理方法,事件表加消息队列,订单的迁移触发发货单的迁移。实际修改过程中还碰到很多具体问题,发了两次消息才最终达成一致,不过这些都是细节了。
这里需要提醒的是,迁移程序的数据库信息最好都是可配置的,以防上线过程中数据库地址、schema、用户名等临时变更。
监控和BI
这些在当时的上下文下优先级偏低,在第一次上线时,对于不能及时调整的,都先做了屏蔽处理,不过处理的思路和上面类似。
以上的这些步骤基本上和《Refactoring Databases》中提到的如下步骤不谋而合。
Test before, during, and after
Modify the database schema
Migrate the source data
Refactor external access program(s)
Run your regression tests
Version control your work
Announce the refactoring
上线
因为上线之前发货单的数据库一直在同步主库的数据,并且上线过程中同步仍然保持,理论上上线可以做到不停机。但是如果存在高并发的情况,主从binlog同步延迟大,很可能会造成部分脏数据,保险起见短暂的停机上线比较安全。
其实上面提到的问题,理论上是新老两个版本同时在线上运行造成的。其中一个典型的例子就是灰度发布,但是灰度发布往往在数据上是隔离的,唯一要考虑的是配置项能不能区分开,因为当前微服务往往会从配置服务器中取配置。如果配置项中不支持灰度实例配置项,就要特别注意。
这里也有两种方法可以选择:
- 新版本读取另一个变量。例如老版本读取DB_URL,新版本读取DB_URL_NEW。通过一份配置,多个配置项名称的方式区分开。
- 如果是容器化部署的话,容器的环境变量通常优先级更高,在容器层设置变量覆盖掉Configuration server中的变量。
第二种方法会导致配置项分散,所以优先选择第一种。
另外,上线之后生产环境的测试必不可少。测试环境再如何测试也不能百分百保证生产环境一定没问题。条件允许的情况下,多测一些修改过的地方和系统的关键功能。
总结
回顾整个拆库流程,整体的策略还是对的。先找到数据库的瓶颈,把一部分拆分出去,梳理清楚整个流程,之后进一步的细分,就水到渠成了。
但是数据库重构和代码重构有相似之处,也有不同之处。
相似之处在于修改的过程中基本的思路是一致的,测试->修改->测试,小步快跑,反复迭代。
不同之处在于拆库还依赖于硬件的基础设施,这就更要求测试环境尽量去模拟生产环境。总结下来,整个过程出了两个问题都是没有完全模拟生产环境导致的:
- 测试环境通过不同用户授权的形式做逻辑划分,导致有一张表存在一个服务写入,其他服务读取的情况没有在测试环境发现。
- 测试环境的schema和生成环境的名称不一致,导致漏掉了历史库迁移程序的修改。
好在这两个问题都及时发现,并很快纠正了过来。
在实际中,可能每个拆库的场景都不尽相同,没有绝对适用的流程方法,需要因地制宜,灵活操作。
最后,不管是业务代码的修改还是数据库的修改,最怕的是有些场景没想到。一旦想到了,解决的办法总是有的。
希望本文介绍的实践对你有帮助。
文/Thoughtworks冯博
原文链接:https://insights.thoughtworks.cn/database-split-practice/
更多精彩洞见,请关注微信公众号Thoughtworks洞见。