
1.Word2vec介绍
1.1 Word Embedding介绍
- WordEmbedding将「不可计算」「非结构化」的词转化为「可计算」「结构化」的向量.

1.2 Word2vec 基本内容
- Word2vec是google的一个开源工具,能够根据输入的词计算出词与词之间的距离.
- Word2vec将term转换成向量形式,可以把对文本内容的处理简化为向量运算,计算出词向量的相似度,来表示文本语义上的相似度。
- 词向量:用Distributed Representation表示词,通常也被称为“Word Representation”或“Word Embedding(嵌入)”。
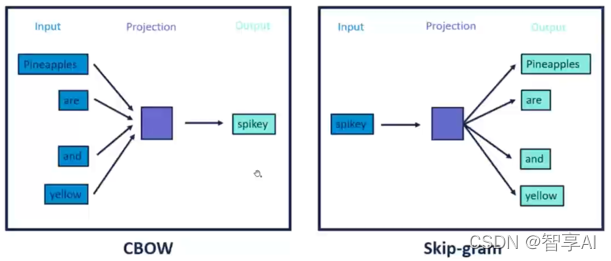
1.3 Word2vec的两种训练方法
- CBOW:通过上下文预测中心词。
- Skip-Gram:通过中心词预测上下文。
2. 数据集及工具库介绍
2.1 数据集:中文维基百科语料库
-
下载地址: https://dumps.wikimedia.org/zhwiki/
-
尽可能下载大一些的,语料库越大,模型的效果会越好.
-
本案例下载的是:
1.https://dumps.wikimedia.org/zhwiki/latest/zhwiki-latest-pages-articles.xml.bz2
2.数据集的大小为1.8G

3 中文词向量训练的数据预处理
3.1 代码实现
"""解析XML文件:process_wiki_data.py"""
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# process_wiki_data.py 用于解析XML,将XML的wiki数据转换为text格式
import logging
import os.path
import sys
from gensim.corpora import WikiCorpus
if __name__ == '__main__':
# sys.argv[0]获取的是脚本文件的文件名称
program = os.path.basename(sys.argv[0])
# sys.argv[0]获取的是脚本文件的文件名称
logger = logging.getLogger(program)
# format: 指定输出的格式和内容,format可以输出很多有用信息,
# %(asctime)s: 打印日志的时间
# %(levelname)s: 打印日志级别名称
# %(message)s: 打印日志信息
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
# 打印这是一个通知日志
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 3:
print (globals()['__doc__'] % locals())
sys.exit(1)
inp, outp = sys.argv[1:3]
# inp:输入的数据集
# outp:从压缩文件中获得的文本文件
space = " "
i = 0
output = open(outp, 'w', encoding='utf-8')
wiki = WikiCorpus(inp, lemmatize=False, dictionary={})
for text in wiki.get_texts():
output.write(space.join(text) + "\n")
i = i + 1
if i % 200 == 0:
logger.info("Saved " + str(i) + " articles")
break
output.close()
logger.info("Finished Saved " + str(i) + " articles")
"""分词文件:seg.py"""
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# seg.py 用于解析wiki.zh.text,生成分词文件
import jieba
import jieba.analyse
import codecs
# 将文本文件分词
def process_wiki_text(origin_file, target_file):
with codecs.open(origin_file, 'r', 'utf-8') as inp, codecs.open(target_file,'w','utf-8') as outp:
line = inp.readline()
line_num = 1
while line:
print('---- processing ', line_num, 'article----------------')
line_seg = " ".join(jieba.cut(line))
# print(len(line_seg))
outp.writelines(line_seg)
line_num = line_num + 1
line = inp.readline()
if line_num == 101:
break
inp.close()
outp.close()
def main():
process_wiki_text('wiki.zh.text', 'wiki.zh.text.seg')
if __name__ == '__main__':
main()